
今天给大家介绍一篇斯坦福大学的 ICLR'22 论文。该文在 OpenReview 中获得了8/8/8/8的高分。文章解决的是预训练模型的长文本生成问题。做过文本生成的同学应该都见识过,如今的 GPT2 等一众大规模生成模型在生成短文本时可以做到十分流畅;但是做长文本生成的时候就开始前言不搭后语,一致性很差。比如,可能前面还在严肃地针砭时事,后面就突然画风走偏,聊起自己的兴趣爱好、家长里短。这是完全有可能的,因为预训练语言模型在做生成时是完全没有长期规划能力的。
那早此之前的解决方法,基本就是把长文本生成问题拆解为两个步骤:先写提纲,再根据提纲做条件生成。那列提纲的方式也有两种。常见的一种是列“显式的提纲”。和我们平时写提纲的方式差不多,把核心内容先提前规划出来。
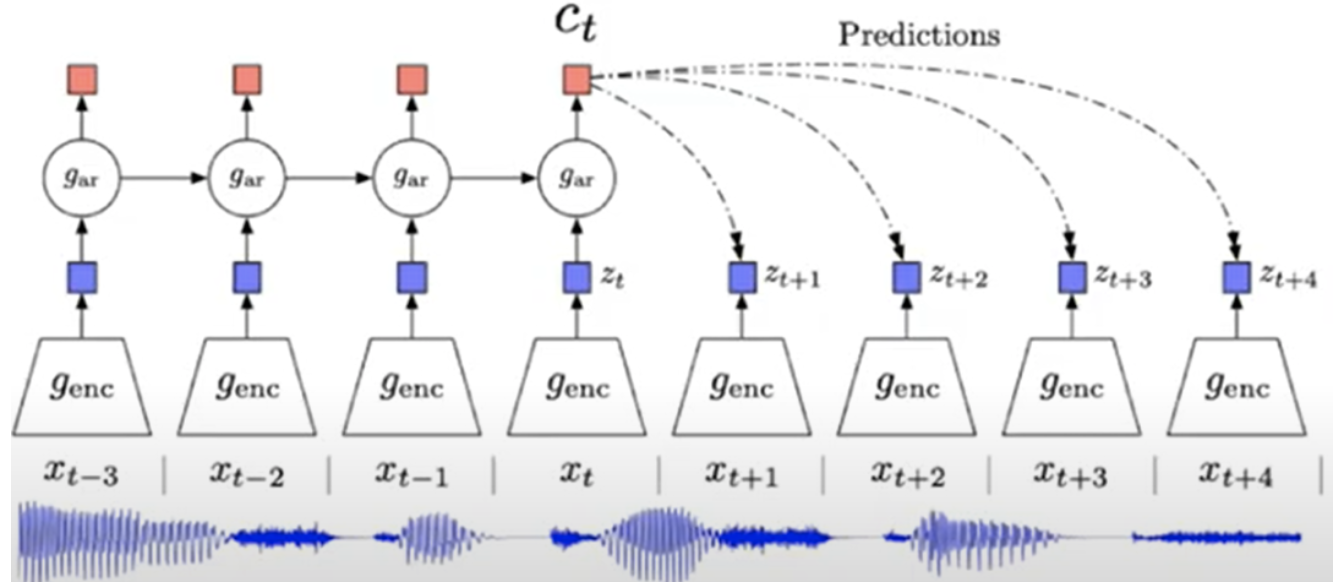
而本文的方法可以理解为“隐式的提纲”:假设每个词背后都有一个隐向量,而该词是基于该隐向量条件生成的,如下图所示。于是,长文本生成的规划问题就变成了学习预测文本在隐空间中的移动轨迹。本文进一步提出了两个假设:
-
文本在隐空间中的移动可以建模为布朗运动的过程。通俗一点解释就是:相邻文本应该有相近的隐空间表示。这也就保证了局部流畅性。 -
目标导向的长文本规划中,文本在隐空间中的移动轨迹应当有固定的起点和重点,也就是应当遵从布朗桥过程。
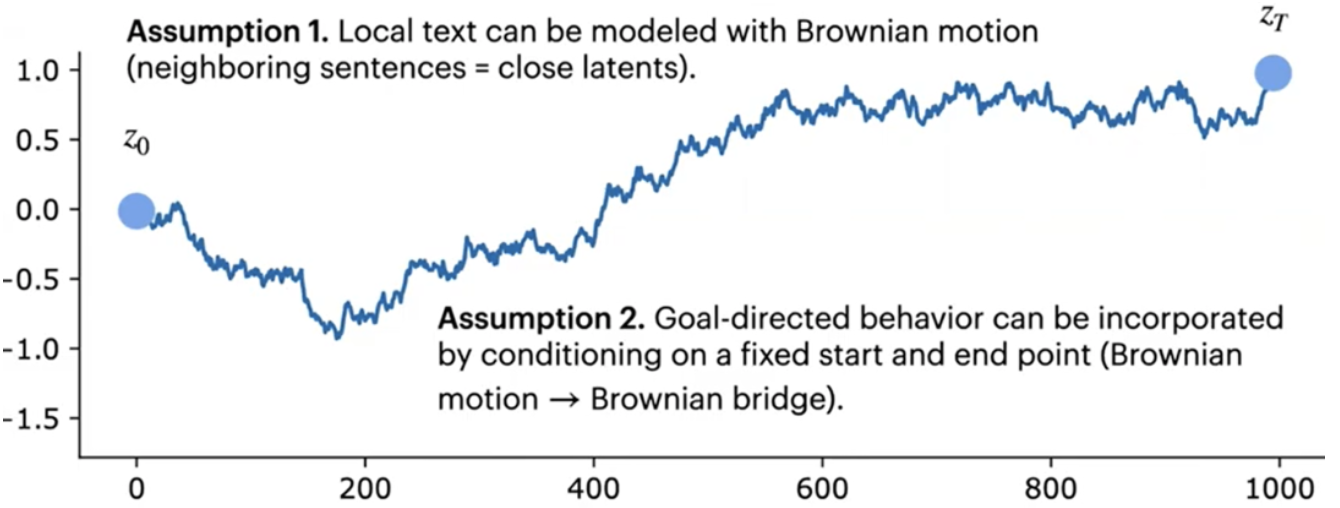
接下来,我们具体看看方法部分——本文是如何基于以上两个假设,实现有规划的文本生成?
论文标题:
Language modeling via stochastic processes
论文链接:
https://arxiv.org/abs/2203.11370
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢