
作者:Jiuxiang Gu, Jason Kuen, Vlad I. Morariu,等
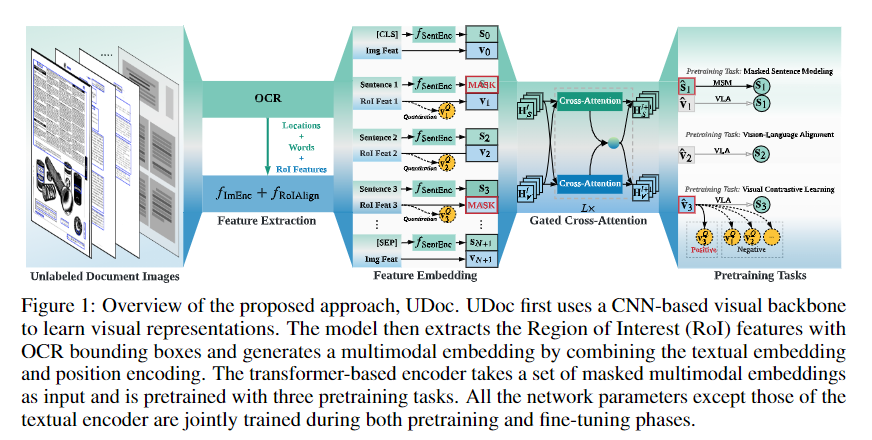
简介:本文研究在文档预训练任务中增加文档理解与多模态等方法。文档智能自动从文档中提取信息并支持许多业务应用程序。最近在大规模未标记文档数据集上的自监督学习方法为通过训练具有自监督目标的模型来减少注释工作开辟了有希望的方向。然而,大多数现有的文档预训练方法仍然以语言为主。作者提出了 UDoc:一个用于文档理解的新的统一预训练框架。UDoc 旨在支持大多数文档理解任务,扩展 Transformer 以将多模态嵌入作为输入。每个输入元素由来自输入文档图像的语义区域的单词和视觉特征组成。UDoc 的一个重要特征是它通过利用三个自监督损失来学习通用表示,鼓励表示来建模句子,学习相似性并调整模态。广泛的实证分析表明,预训练过程学习了更好的联合表示并导致下游任务的改进。

论文下载:https://arxiv.org/pdf/2204.10939
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢