
【论文标题】Translation between Molecules and Natural Language
【作者团队】Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Heng Ji
【发表时间】2022/04/26
【机 构】伊利诺伊香槟、谷歌
【论文链接】https://arxiv.org/pdf/2204.11817v2.pdf
【代码链接】https://github.com/blender-nlp/MolT5
现有研究已经对图像和文本之间的联合表示进行了深入研究,在计算机视觉中,纳入自然语言的好处已经很明显,可以实现图像的语义层面控制。本文提出了MolT5,一个自监督的学习框架,用于对大量未标记的自然语言文本和分子字符串进行预训练模型。MolT5允许对传统的视觉语言任务进行新的、有用的和具有挑战性的模拟,如分子说明和基于文本的新分子生成,即分子和语言之间的翻译。此外,由于MolT5在单模态数据上预训练模型,它有助于克服化学领域数据稀缺的缺点。此外,本文考虑了几个指标,包括一个新的基于跨模态嵌入的指标,以评估分子描述和基于文本的分子生成任务。通过将分子与自然语言相连接,本文能够对分子的发现和理解进行更高层次的语义控制,这是药物发现和材料设计等科学领域的关键任务。本文的研究结果表明,基于MolT5的模型能够生成分子和文本,在许多情况下,这些输出都是高质量的,并且与输入模式相匹配。在分子生成方面,本文最好的模型达到了30%的精确匹配测试精度,为本文保持的测试集中大约三分之一的标题生成了正确的结构。
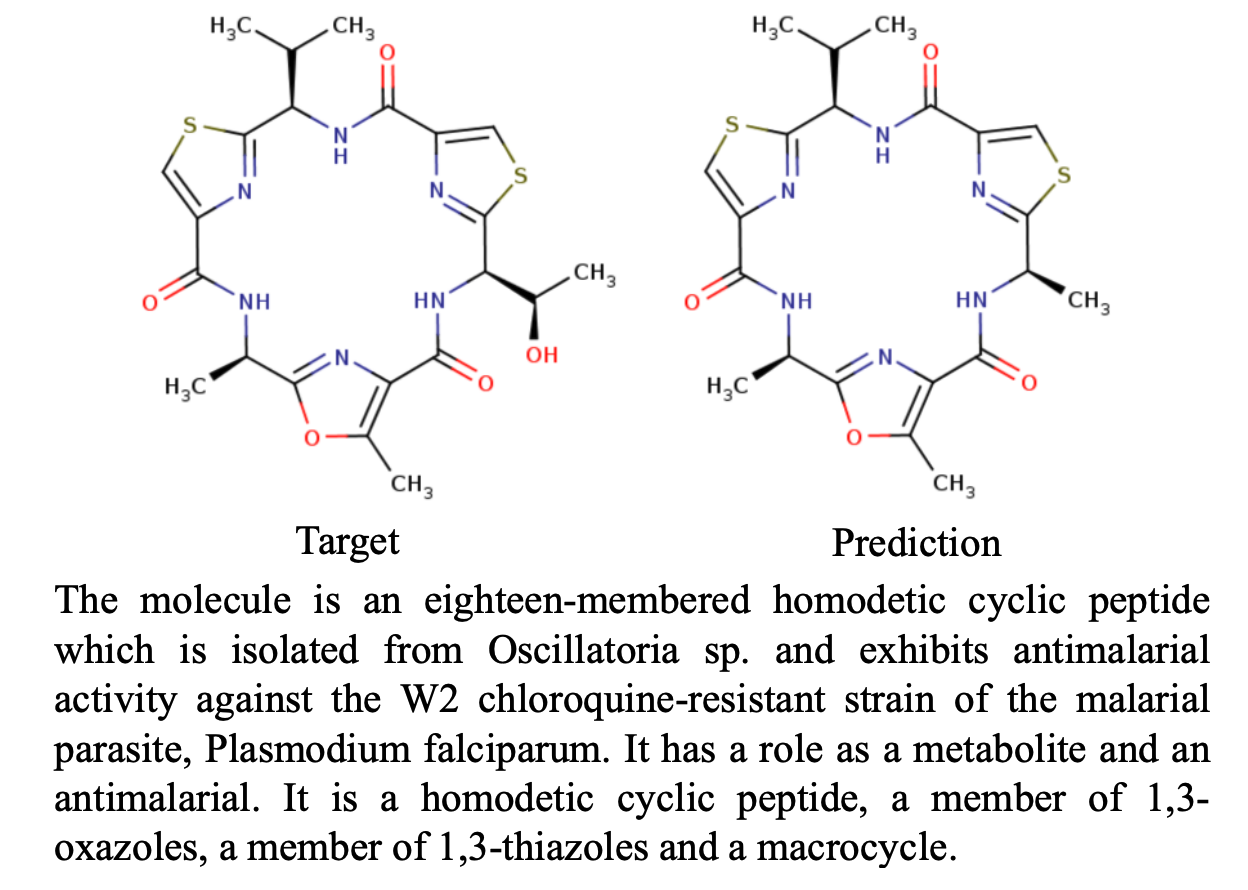
上图为一个模型在分子生成任务中的一个输出例子,左边是真实分子,右边是根据给定的自然语言描述生成的分子。本文通过提出两个新的任务来追求分子和语言之间的翻译这一宏伟目标:分子描述和文本指导的新分子生成。在分子描述中,采用一个分子(例如,作为一个SMILES字符串)并生成一个描述它的说明;在文本指导的分子生成中,任务是创建一个符合给定自然语言描述的分子
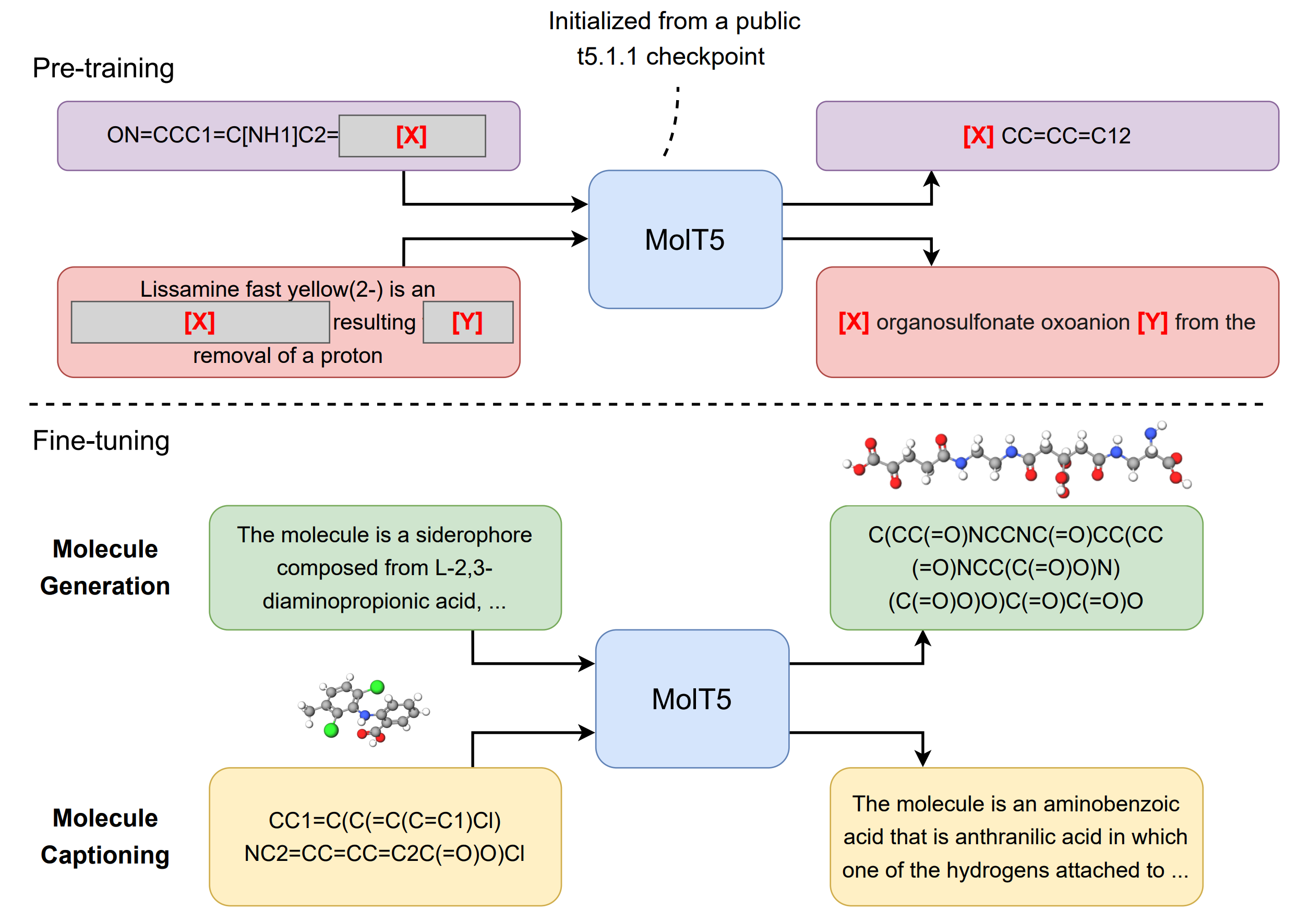
上图展示了MolT5框架。首先使用T5.1.12的一个公共检查点初始化一个编码器-解码器Transformer模型,这是T5的一个改进版本。之后,我们使用 "替换损坏的span "目标对模型进行预训练,更具体地说,在每个预训练步骤中,我们对包括自然语言序列和SMILES序列的minibatch进行采样。对于每个序列,序列中的一些词被随机选择用于破坏,每一个连续的被破坏的标记被一个标记所取代,上图显示为[X]和[Y]。然后,任务是预测被迫害的span。在预训练阶段之后,MolT5可以很容易地针对分子描述或生成任务或两者进行微调。
预训练过程结束后,可以对预训练的模型进行微调,以便进行分子描述或生成。在分子生成中,输入是描述,而输出是目标分子的SMILES表示。另一方面,在分子描述中,输入是一些分子的SMILES字符串,而输出是描述输入分子的标题。
数据方面,MolT5的预训练阶段需要两个单语语料库:一个由自然语言文本组成,另一个由分子表示法组成。使用 "Colossal Clean Crawled Corpus"(C4)作为文本模式的预训练数据集。对于分子模态,直接利用Chemformer中使用的1亿个SMILES字符串,这些字符串是从ZINC-15数据集中挑选出来的。
创新点
1.本文提出了两个新任务:分子描述,即为给定的分子生成描述;2.基于文本的新分子生成,即生成一个与给定文本描述相匹配的分子。
2. 本文为这些新任务考虑了多种评价指标,并提出了一个基于Text2Mol(Edwards等人,2021)的新的跨模态检索相似度指标。
3. 提出了MolT5:一个自监督的学习框架,用于联合训练分子字符串表征和自然语言文本的模型,然后在跨模态任务中进行微调。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢