
【标题】A Hierarchical Bayesian Approach to Inverse Reinforcement Learning with Symbolic Reward Machines
【作者团队】Weichao Zhou, Wenchao Li
【发表日期】2022.4.20
【论文链接】https://arxiv.org/pdf/2204.09772.pdf
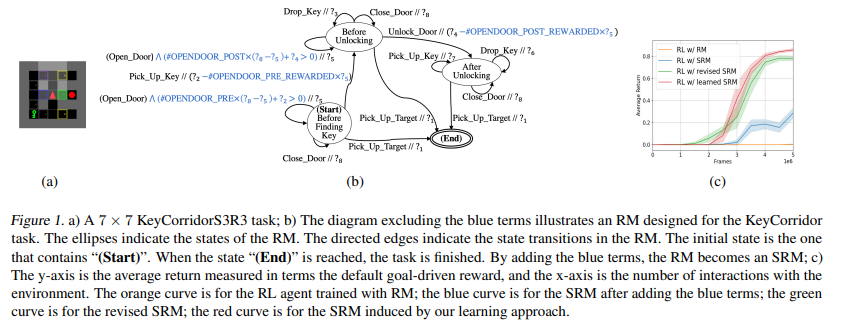
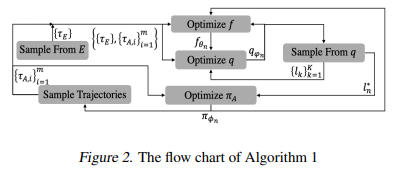
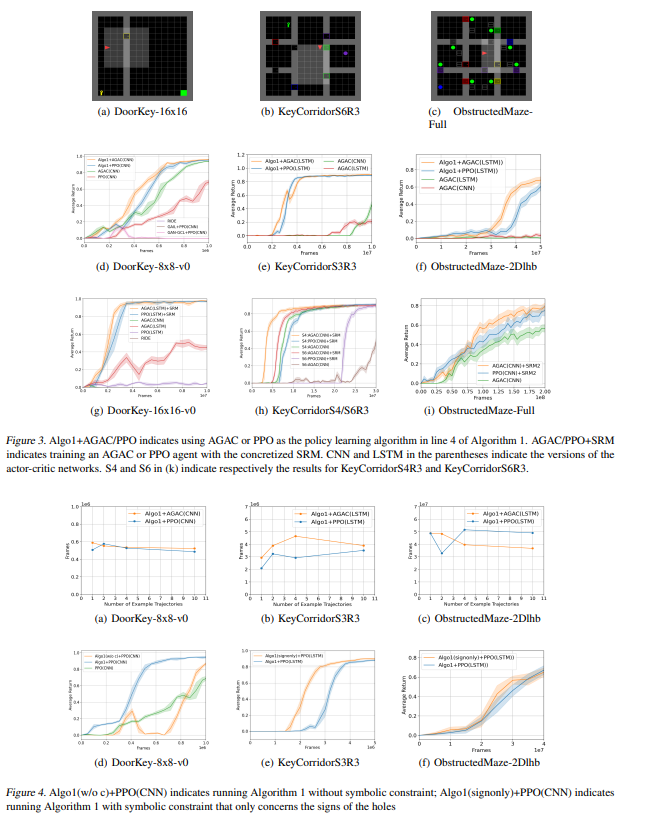
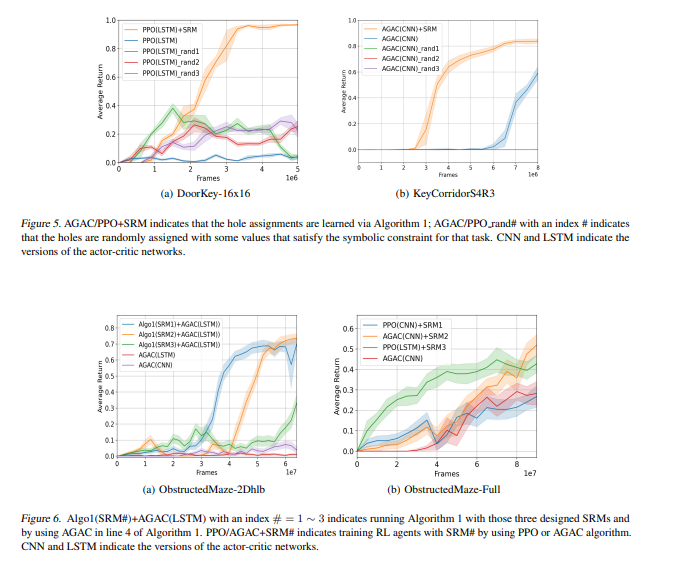
【推荐理由】在强化学习(RL)问题中,错误指定的奖励会降低样本效率并导致不期望的行为。本文提出了符号奖励机制,用于在指定奖励信号时结合高级任务知识。符号奖励机通过允许转换携带谓词和符号奖励输出来扩充现有的奖励机形式。这种形式很适合反向强化学习,其中的关键挑战是确定一些专家演示中符号值的适当分配。其提出了一种分层贝叶斯方法来推断最可能的分配,以便具体化的奖励机制可以高精度地将专家演示的轨迹与其他轨迹区分开来。实验结果表明,学习的奖励机制可以显著提高复杂RL任务的训练效率,并在不同任务环境配置下具有良好的通用性。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢