
【标题】SAAC: Safe Reinforcement Learning as an Adversarial Game of Actor-Critics
【作者团队】Yannis Flet-Berliac, Debabrota Basu
【发表日期】2022.4.20
【论文链接】https://arxiv.org/pdf/2204.09424.pdf
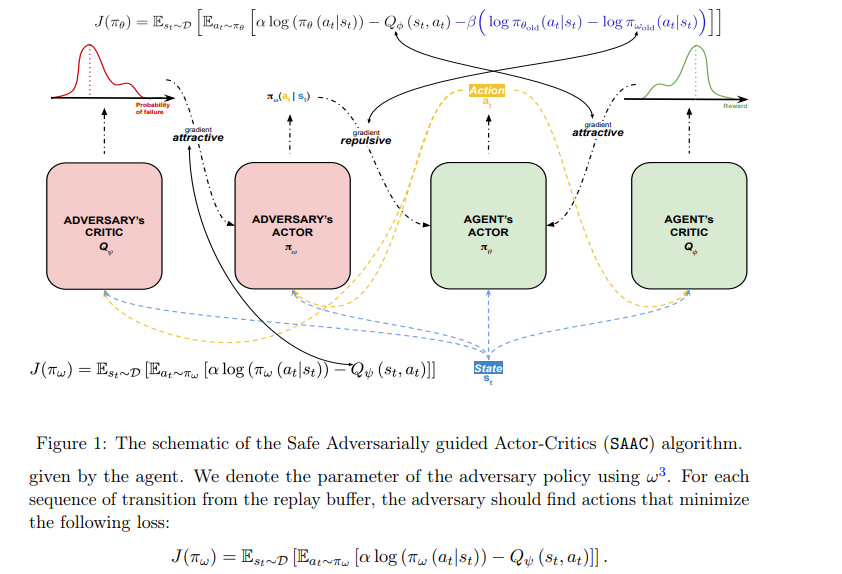
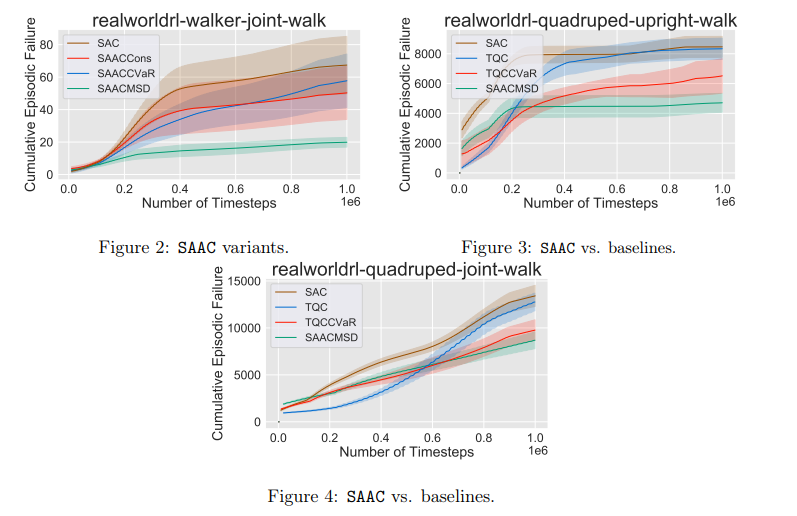
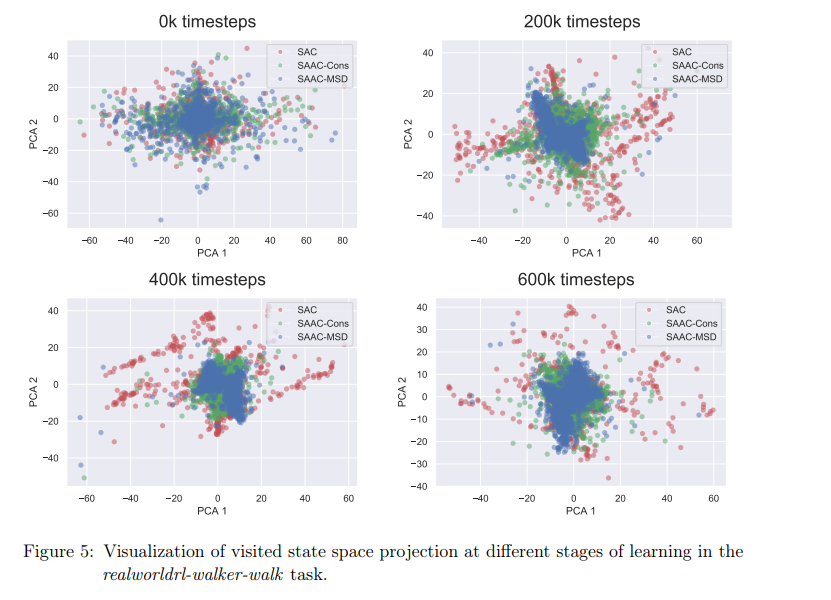
【推荐理由】尽管强化学习(RL)对不确定性条件下的连续决策问题有效,但它仍然无法在风险或安全是约束约束的现实世界系统中蓬勃发展。本文将具有安全约束的RL问题描述为一个非零和博弈。虽然使用最大熵RL部署,但该公式会产生安全的对抗引导软参与者批评框架,称为SAAC。其对手的旨在打破安全约束,而RL智能体的目标是在对手的策略下最大化约束价值函数。对智能体价值函数的安全约束只表现为代理人和对手策略之间的排斥项。与先前方法不同,SAAC可以解决不同的安全标准,如安全勘探、均值-方差风险敏感性和类似CVaR的一致性风险敏感性。举例说明了对手针对这些约束的设计。并在每一种变体中,展示了智能体除了学习解决任务之外,还将自己与对手的不安全行为区分开来。最后,对于具有挑战性的连续控制任务,我研究表明了SAAC比风险规避分布RL和风险中性软参与者批评算法收敛更快、效率更高,且在满足安全约束方面的失败次数更少。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢