
作者:Yasumasa Onoe, Michael J.Q. Zhang, Eunsol Choi, 等
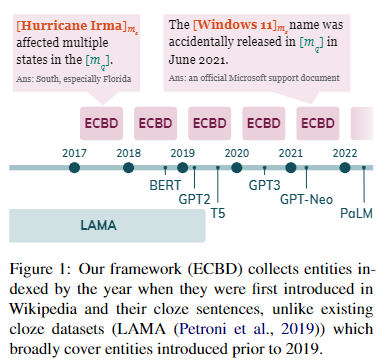
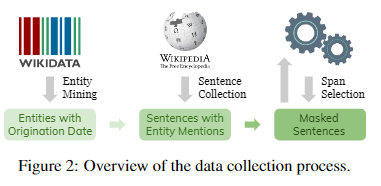
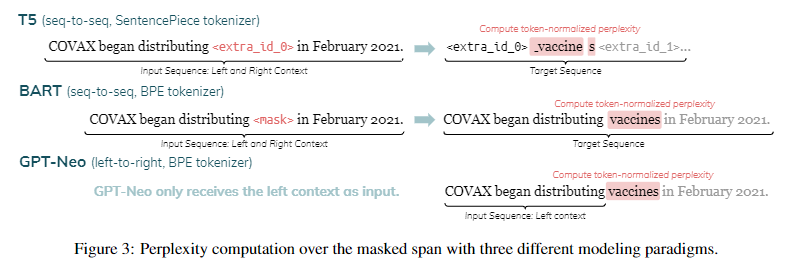
简介:本文研究预训练语言模型的实体感知议题。语言模型 (LM) 通常在大规模语料库上训练一次,并且可以使用多年而无需更新。然而,在一个动态的世界中,新的实体不断出现。作者提出了一个框架来分析 LM 可以推断出在 LM 预训练时不存在的新实体。作者导出了一个实体数据集,该数据集按其起源日期进行索引,并与英文维基百科文章配对,从中作者可以找到关于每个实体的句子。作者评估 LMs 在这些句子中的掩码跨度上的困惑。作者表明,模型对实体更了解(例如那些可以访问它们的文本定义的模型,在这个基准上实现了更低的困惑)。作者的实验结果表明,对于 LM 来说,对新实体进行推断仍然很困难。鉴于其对实体知识和时间索引的广泛覆盖,作者的数据集可用于评估旨在修改或扩展其知识的 LM 和技术。作者的自动数据收集管道可轻松用于不断更新作者的基准。
论文下载:https://arxiv.org/pdf/2205.02832.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢