
作者:Thilini Wijesiriwardene , Vinh Nguyen , Goonmeet Bajaj ,等
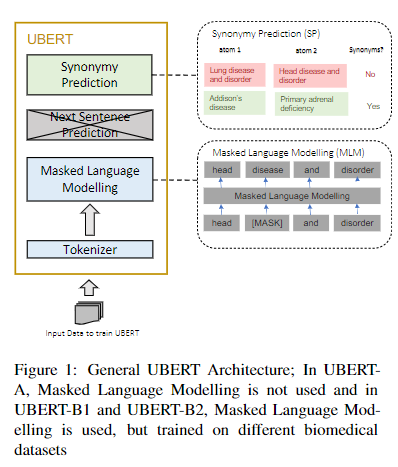
简介:本文研究生物医学大规模同义词预测的语言模型。UMLS Metathesaurus 整合了 200 多个生物医学源词汇。在 Metathesaurus 构建过程中,同义词由人工编辑器聚类成概念,并辅以词汇相似度算法。此过程容易出错且耗时。最近,针对 UMLS 词汇对齐 (UVA) 任务开发了一种深度学习模型 (LexLM)。这项工作介绍了 UBERT,这是一种基于 BERT 的语言模型,通过监督同义词预测 (SP) 任务替换原始的下一句预测 (NSP) 任务对 UMLS 术语进行预训练。使用 UMLS 词汇对齐 (UVA) 任务评估 UBERT 对 UMLS Metathesaurus 构建过程的有效性。作者展示了 UBERT 优于 LexLM 以及基于生物医学 BERT 的模型。
论文下载:https://arxiv.org/pdf/2204.12716
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢