

论文链接:https://arxiv.org/pdf/2107.12292.pdf
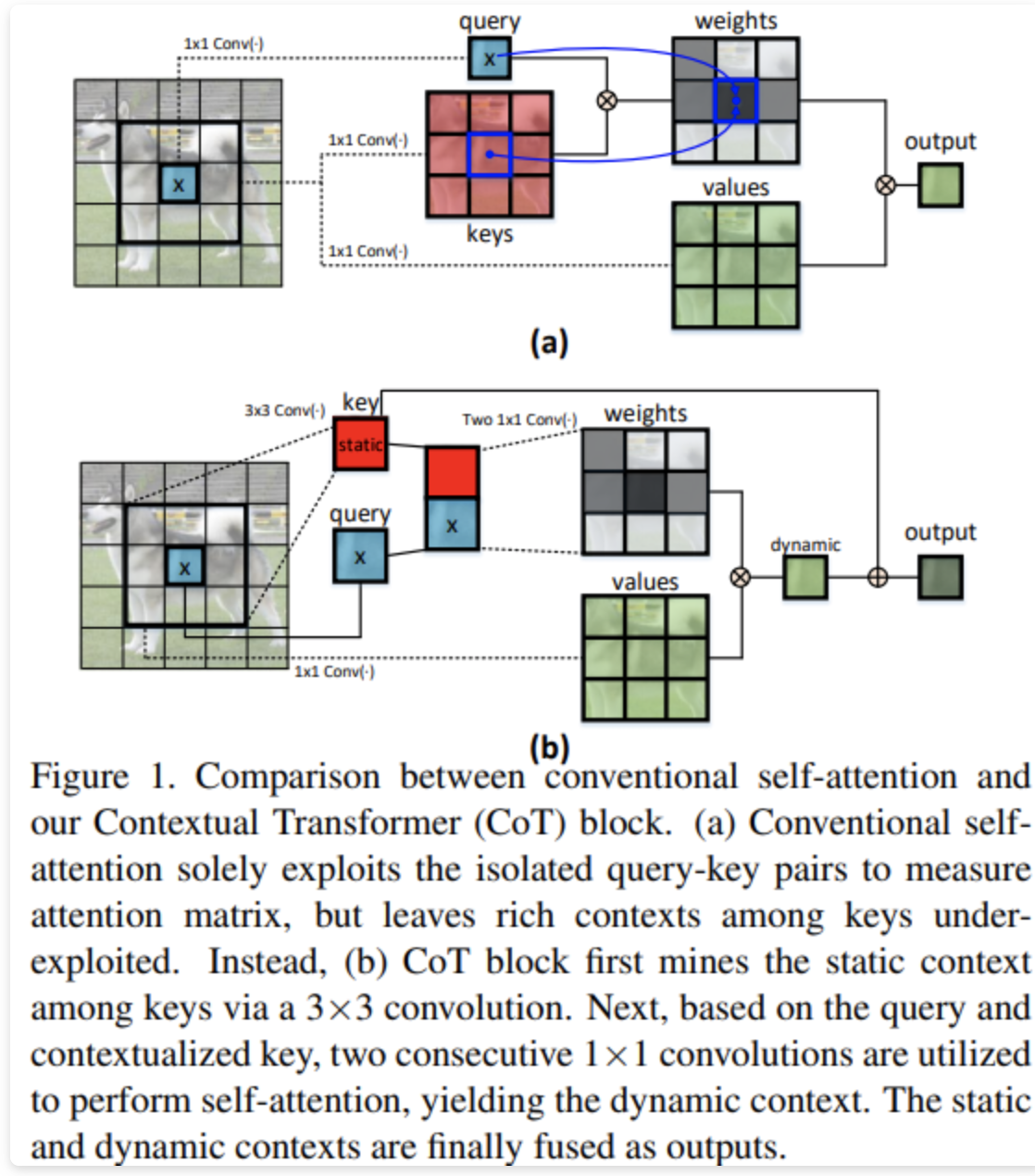
近年来,Transformer 不但开启了自然语言处理领域的新里程,而且随着基于 Transformer 的架构设计出现,在众多的计算机视觉任务中也取得了具有竞争力的结果。然而,大多数现有的基于 Transformer的架构设计是直接作用在 2D 特征图上的,通过使用自注意力来获得注意力矩阵(独立的查询点(queries) 和所有键(keys)),但未充分利用相邻键之间的丰富上下文。在这项工作中,我们设计了一个新颖的 Transformer 模块,即 Contextual Transformer (CoT) 用于视觉识别。这种设计充分利用输入键之间的上下文信息来指导动态注意力矩阵的学习,从而增强视觉表示能力。从技术上来看,CoT 首先通过 3 × 3 卷积对输入键进行上下文编码,从而产生输入的静态上下文表示。进一步地,我们将经过编码的键与输入查询连接起来,通过两个连续的 1×1 卷积学习动态多头注意力矩阵。最后,学习到的注意力矩阵乘以输入值以实现输入的动态上下文表示,并且融合静态和动态上下文表示作为最终输出。CoT 是一个即插即用的模块 ,通过替换 ResNet 架构中的每个 3 × 3 卷积,我们可以得到 Contextual Transformer Networks (CoT-Net)。我们在不同任务中进行了(例如图像识别、对象检测和实例分割)大量实验,验证了 CoT-Net 有效性和优越性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢