
Vision Transformer由于其较高的模型性能在计算机视觉领域受到广泛关注。然而,Vision Transformer受到大量参数的影响,限制了它们在内存有限的设备上的适用性。为了缓解这一问题,本文提出了一种新的压缩框架MiniViT,MiniViT能够在保持相同性能的同时实现了Vision Transformer的参数缩减。
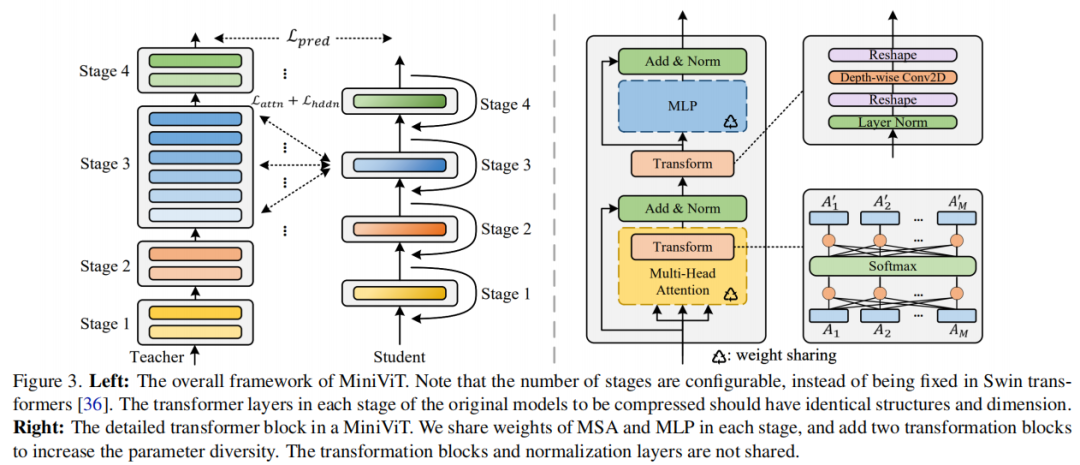
MiniViT的核心思想是将连续Vision TRansformer Block的权重相乘。更具体地说,使权重跨层共享,同时对权重进行转换以增加多样性。Weight distillation也被应用于将知识从Large-scale ViT模型转移到权重复用的紧凑模型。
综合实验证明了MiniViT的有效性,MiniViT可以将预训练的Swin-B Transformer的尺寸减少48%,同时在ImageNet上Top-1准确率提高了1.0%。此外,使用单层参数,MiniViT能够将DeiT-B压缩9.7倍,从86M到9M的参数,而不会严重影响性能。最后,通过MiniViT在下游基准上的性能来验证其可迁移性。

论文链接:
https://arxiv.org/abs/2204.07154
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢