标题:谷歌|CoCa: Contrastive Captioners are Image-Text Foundation Models(CoCa:对比字幕生成器是图像-文本基础模型)
作者:Jiahui Yu, Zirui Wang, Yonghui Wu等
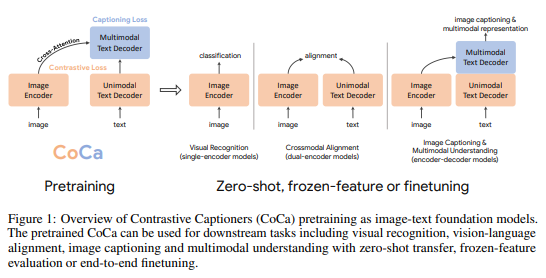
简介:本文介绍了一个图像领域当前最佳的基础模型。本文介绍了对比字幕 (CoCa),这是一种极简设计,用于预训练图像-文本编解码基础模型以及对比损失和字幕损失,从而将模型能力从对比方法(如 CLIP)和生成方法(如 SimVLM)中纳入。作者在单峰图像和文本嵌入之间应用了对比损失,此外还对多模解码器输出的字幕损失进行了自回归预测文本标记。通过共享相同的计算图,可以以最小的开销有效地计算两个训练目标。CoCa 通过将所有标签简单地视为文本,在网络规模的替代文本数据和带注释的图像上端到端和从头开始进行预训练,无缝统一了带监督自然语言的表示学习。根据经验,CoCa 在广泛的下游任务、包括视觉识别、跨模态检索、多模式理解和图像字幕生成的任务特定适应方面实现了最佳性能。值得注意的是,在 ImageNet 分类中,CoCa 获得了 86.3% 的零样本top-1 准确率,使用冻结编码器和学习分类头获得了90.6%,以及在ImageNet上使用微调编码器获得了最先进的 91.0% top-1 准确率。
论文下载:https://arxiv.org/pdf/2205.01917v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢