

论文链接:
http://arxiv.org/abs/2204.07955
代码链接:
https://github.com/NUSTM/VLP-MABSA
最近,有少数工作提出对多模态属性级情感分析任务进行多模态预训练。但是这些工作主要使用了通用的预训练任务,如图像-文本对齐任务和掩码语言模型任务。这些通用的预训练任务不足以挖掘细粒度的属性、观点信息以及它们在图像和文本模态间的对齐信息。
为了解决上述问题,本文针对多模态属性级情感分析任务,提出了一个任务特定的视觉-语言预训练模型(VLP-MABSA)。
-
文本模态预训练:1)掩码语言模型;2)文本属性-观点抽取。
-
视觉模态预训练:1)掩码区域模型;2)视觉属性-观点生成。
-
多模态预训练:1)多模态情感预测。
综合进行这三类预训练任务可以很好地获取图像和文本模态中对于多模态属性级情感分析任务重要的细粒度主客观信息以及两者的对齐信息,从而有助于多模态细粒度情感分析任务性能的提升。
实验结果表明提出的预训练模型(VLP-MABSA)在多模态属性级情感分析的三项子任务上与当前方法相比取得了领先的性能。
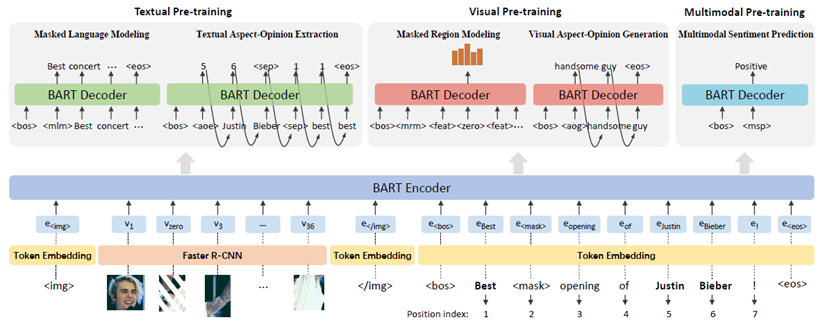
预训练的整体框架
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢