
【论文标题】FINETUNA: Fine-tuning Accelerated Molecular Simulations
【作者团队】Joseph Musielewicz, Xiaoxiao Wang, Tian Tian, Zachary Ulissi
【发表时间】2022/05/02
【机 构】卡耐基梅隆
【论文链接】https://arxiv.org/pdf/2205.01223v1.pdf
【代码链接】 https://github.com/ulissigroup/finetuna_manuscript
应对气候变化所需的能源突破可以通过原子系统的有效模拟而大大加快。然而,基于第一原理的模拟技术,如密度泛函理论(DFT),由于其高计算费用,在实际使用中受到限制。机器学习方法有可能以一种计算效率高的方式来近似DFT,这可以极大地提高计算模拟对现实世界问题的影响。然而,它们受到其准确性和生成标记数据的成本的限制。本文提出了一个在线主动学习框架,通过纳入由开放催化剂项目的大规模预训练图神经网络模型所学到的先验物理信息,有效而准确地加速原子系统的模拟。加速模拟可以更便宜地产生有用的数据,允许更好的模型被训练和更多的原子系统被筛选。本文还提出了一种在速度和准确性的基础上比较局部优化技术的方法。在30个基准吸附剂-催化剂系统上的实验表明,迁移学习方法将来自预训练模型的先验信息纳入其中,通过减少91%的DFT计算次数来加速模拟,同时在93%的时间内达到0.02eV的精度阈值。最后,本文展示了一种技术,利用VASP内置的互动功能,在本文的在线主动学习框架内有效地计算单点计算,而不需要大量的启动成本。这使得VASP能够与本文的框架协同工作,同时需要比传统的单点计算少75%的自洽周期。
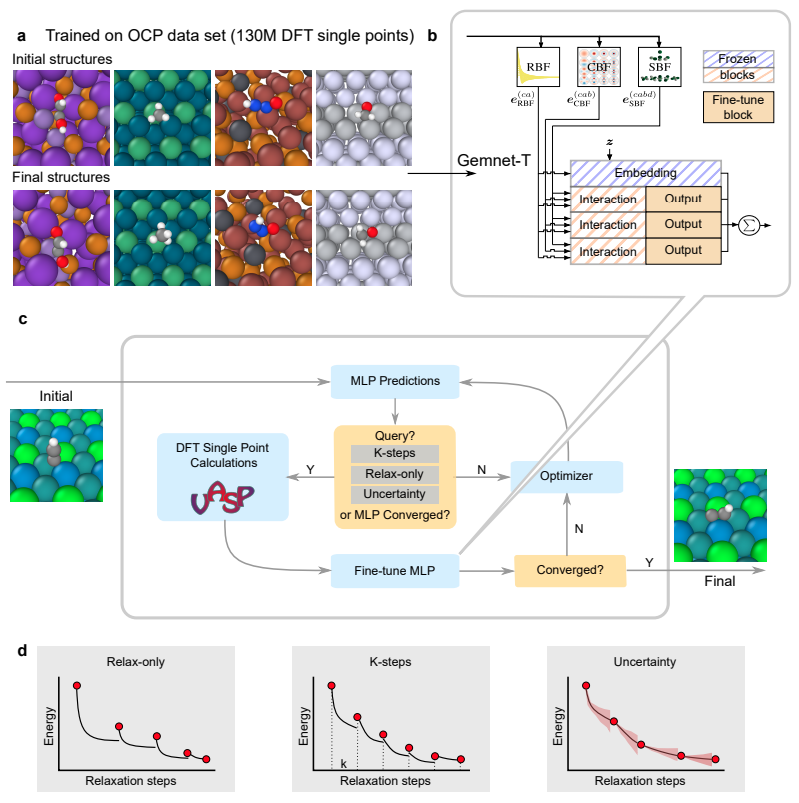
GemNet模型和在线主动学习器的工作流程。
(a) 在OC20数据集中,GemNet模型预训练的案例,参考论文:J. Gasteiger, F. Becker, and S. Günnemann, “Gemnet: Universal directional graph neural networks for molecules,” arXiv:2106.08903, 2021.。
(b) 微调GemNet。在微调过程中,除了最后一层的输出块,所有的嵌入、交互和输出块都被冻结。该框架使用机器学习势能来加速原子系统的几何优化,以实现力场的估计。上图描述的机器学习势能,通过对优化过程中产生的数据进行拟合来改善。该框架还使用了一个parent计算器,也就是VASP在这项工作中扮演的角色,来计算DFT能量和力场,作为生成数据的基础真实标签。
(c) 在线主动学习工作流程。与更标准的优化方法以及与其他主动学习框架相比,这个框架的优势在于纳入了预训练好的机器学习势能的先验信息。在这项工作中,作者使用了一个预训练好的名为GemNet-T的图神经网络作为机器学习势能的基础。图神经网络最近在接近吸附剂-催化剂系统的DFT计算方面显示出巨大的成功,根据OCP leaderboard,GemNet-T是目前其中最先进的。用GemNet-T进行能量和力的预测相对于DFT来说是很便宜的,在一个CPU核心上只需几秒钟,而DFT在一个CPU核心上则需要几小时。然而,GemNet-T缺乏可靠地找到具有局部最小能量的结构所需的精度,而且从头开始训练的成本很高,所以我们使用relax中的parent数据对其进行了即时微调。在微调过程中,我们从预训练好的模型开始,使用AdamW优化器只对GemNet-T的一个输出块进行训练,训练方法的目标是保留GemNet-T模型学到的基本物理信息,同时提高模型的准确性,特别是对它所帮助优化的原子系统。这种对大型预训练模型进行微调以在不同领域之间 "迁移移 "其知识的过程,在机器学习的其他领域有成功的记录。在这项工作中,作者采用了这种策略,在极低的数据制度下,即时改善特定的预测,而不是使用更大的数据集来迁移更多的一般任务。
具体而言,首先使用预训练好的代理模型来预测初始原子结构的能量和力场。然后,优化器使用作为能量梯度的力场来更新原子的位置以减少原子系统的整体能量,新结构的能量和力场再次由代用模型预测。对于每个代理模型的预测,查询标准被用来接受或拒绝该预测。如果预测被接受,优化工作将继续进行;如果它被拒绝,那么就会查询parent计算器。parent计算器被用来计算系统在其当前状态下的真实能量和力场,该计算结果被发送到优化器,而不是代理预测。
(d) 不同查询策略和对比方法:
- VASP CG:内置共轭梯度优化的VASP。
- ASE BFGS。VASP ASE计算器,带有ASE BFGS优化。
- GemNet Warm Start。预训练的GemNet-T计算器与ASE BFGS优化,直到relax,然后从该点开始用ASE VASP计算器与ASE BFGS优化。
- ASE GPMin。ASE内置的优化策略,使用VASP作为parent计算器,并实时训练高斯过程以平滑VASP的势能表面。
- 仅relax的在线学习器。以VASP为parent计算器,以GemNet-T为代理模型的在线学习器。只有当代用模型预测出relaxed结构时,才查询parent计算器并重新训练代用模型。
- K-steps在线学习器。与仅relax的在线学习器相同,但也会在上次查询后的k个步骤中进行查询。
- 不确定性在线学习器。与仅relax型在线学习器相同,同时也在代用模型预测的不确定性指标超过某个阈值时进行查询。
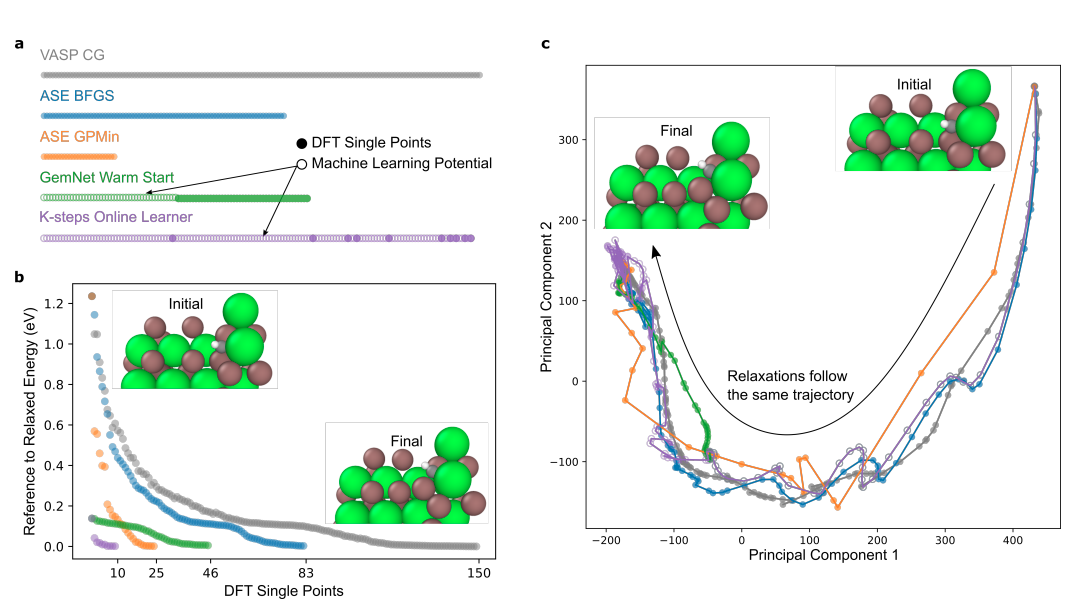
上图展示了一个随机体系的详细比较,其中实心标记代表DFT单点计算,空心标记代表预训练的GemNet预测和微调的GemNet预测。
a图展示了纯DFT运行和MLP参与运行的relax步骤。对于每个策略,可以看到DFT调用是如何沿着轨迹分散的。在GemNet Warm Start和主动学习方法中,第一个DFT点之前的步骤是相同的,因为它们完全依赖于经过训练的GemNet预测。图中显示的主动学习策略是K-steps
b图显示了每次DFT调用时DFTenergy相对于VASP CG的relax能量。相对于VASP CG在每个DFT步骤中的relax能量,可以看到每个策略都收敛到类似的最终能量。在GemNet Warm Start和Activelearning方法中,DFTrelax从比relax能量高0.18eV的能量开始,这表明经过训练的GemNet模型已经将结构relax到接近最终结构。在局部最小值附近的区域(能量小于0.2eV),主动学习的收敛速度远远超过其他方法。因此,relax过程的整体加速是大型预训练GNN模型和主动学习框架的综合效果。
c图为Relax轨迹的主成分分析,可以看到每个策略都遵循类似的路径。

上图展示了所有30个体系的不同优化策略的比较。上图显示每个策略所需的DFT单点计算的数量占VASP CG的百分比。下图显示了相对于VASP CG的relax能量差异。如果不同策略的relax能量在VASP CG参考能量的0.02 eV以内,则是相似的。b图为VASP CG的参考relax结构的可视化。
可以看到,与所有其他方法相比,在线主动学习一直在提高速度,只有极少数的例外情况,即在特定的系统上被ASE GPMin或GemNet Warm Start技术勉强击败了。相比来说主动学习总是击败传统方法,如BFGS和CG,这是可以预期的。就准确性而言,在线主动学习器经常发现与VASP CG和其他方法相同的能量结果。然而,与其他方法相比,它更有可能找到一个较低的最小能量。作者推测,这可能是由于GemNet-T模型的定期微调所带来的噪音。由于优化算法是在不断变化的函数上寻找局部最小值,它可能偶尔会被迫离开浅层局部最小值,因此更有可能找到更深的局部最小值。无论如何,在线主动学习器与ASE BFGS和ASEGPMin一样有可能达到VASP CG设定的阈值以下的局部最小值,这使得它与ASE BFGS和ASE GPMin在这一精度指标上相当,但在速度上一直很出色。
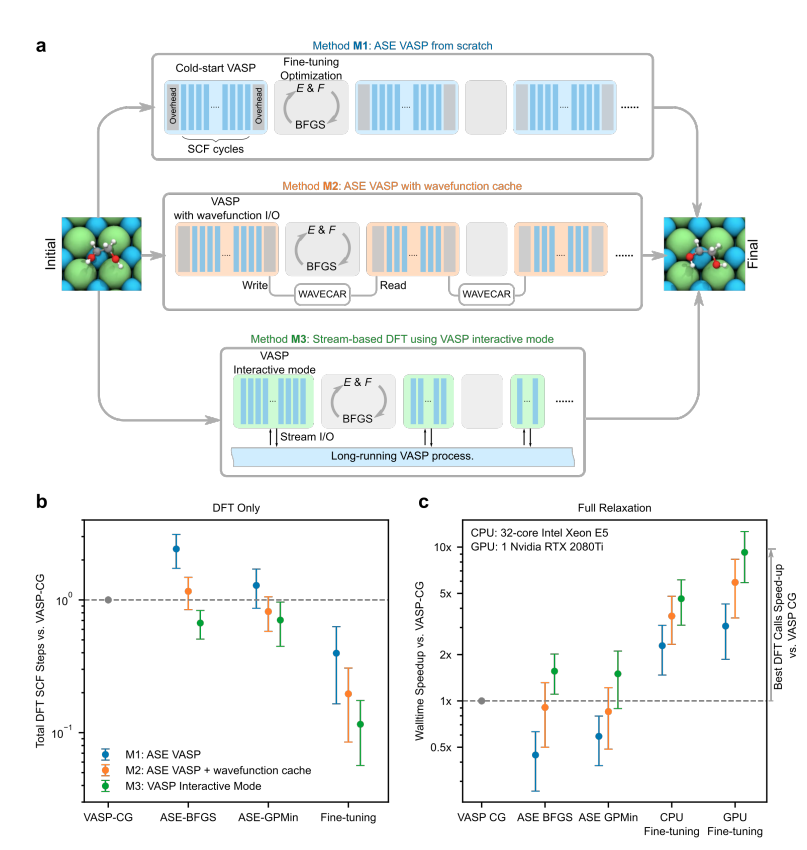
a.主动学习框架中使用的DFT计算器的三种实现方式(M1-M3)之间的示意图比较。
i) 标准ASE VASP(M1):在每个单点上冷启动VASP过程
ii) ASE VASP与波函数缓存(M2):使用本地文件(WAVECAR)来存储和传递单点之间的波函数。
iii) VASPInteractive (M3):基于流的计算器维持一个长期运行的VASP进程。
b.不同优化策略(ASE BFGS,ASE GPMin和MLP)和VASP计算器界面(M1-M3)的DFT SCF循环总量与VASP CG的比较。
c. 与VASP CG相比,不同优化策略(ASE BFGS、ASE GPMin、CPU上的微调和GPU上的微调)和VASP计算器界面(M1-M3)的整个relax过程的walltime速度。使用在线学习器,在GPU上对MLP进行微调,VASPInteractive作为VASP计算器(M3),平均walltime速度接近parentDFT调用的理想速度,
创新点
在这项工作中,作者提出了一个主动学习方案,利用先验信息来加速几何优化。更具体地说,作者使用一个在OC20数据集上预训练的GemNet模型,在新的优化任务重新微调该模型,加速是由主动学习框架实现的,它从势能表面稀疏地查询,避免了不必要的DFT计算。最终表明,微调过程提高了大型GNN模型在每个单独系统上的预测性能,表现最好的主动学习策略减少了91%的DFT单位点计算,93%的最终relax能量接近或低于参考DFTrelax能量。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢