Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis(标注Tweebank 语料库上的命名实体识别和为社交媒体分析构建 NLP 模型)
作者:Hang Jiang, Yining Hua, Doug Beeferman, Deb Roy
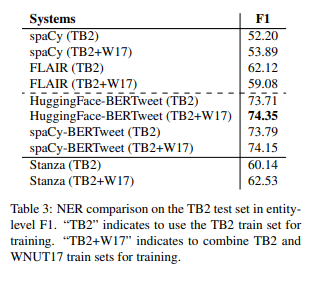
简介:本文介绍了一种新的命名实体识别数据集与模型。作者的目标是创建Tweebank-NER,一个英语NER。基于 Tweebank V2 (TB2) 的语料库,在 TB2 上训练最先进的 (SOTA) Tweet NLP 模型,并发布 NLP 流水线称为Twitter-Stanza。作者使用 Amazon Mechanical Turk 在 TB2 中对命名实体进行注释,并衡量作者的标注质量。作者在 TB2 上训练 Stanza 流水线,并与其他 NLP 框架(例如 FLAIR、spaCy)和基于变换器的模型。Stanza符号器和词形还原器在TB2上实现了SOTA性能,而Stanza NER标记器、词性 (POS) 标记器和依赖关系解析器可实现与非转换器模型相比具有竞争力的性能。基于变换器的模型在Tweebank-NER中建立了强大的基线,并在POS中实现了新的SOTA性能TB2 上的标记和依赖关系解析。
代码下载:https://github.com/social-machines/TweebankNLP
论文下载:https://arxiv.org/pdf/2201.07281v2.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢