

Paper Link: https://arxiv.org/abs/2202.06417
Code Link: https://github.com/yxuansu/SimCTG
导读
近日,腾讯 AI Lab 研发的智能写作助手「文涌(Effidit)」开放试用,依靠AI 技术辅助写作者拓展写作思路、丰富语言表达,提升写作和文本编辑的效率。该助手提供多维度文本补全、多样化文本润色两项核心功能,同时还具备例句推荐、文本纠错、云输入法等功能,构成完整的辅助写作体系。其中,多维度文本补全功能,经多位用户评测,在流利性、丰富性和相关性上,已经与人类水平不相上下,令人眼前一亮。
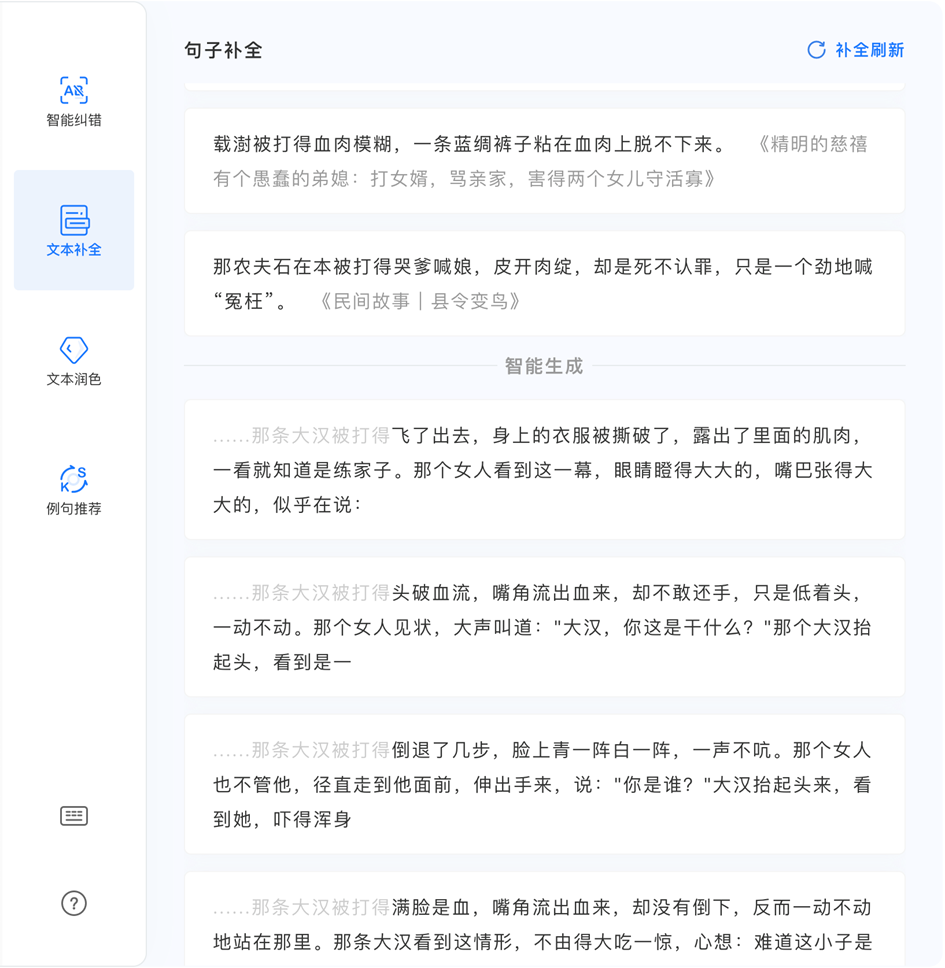
本文将会详细介绍使「文涌」的文本补全效果实现突破的关键技术:由剑桥大学、腾讯AI Lab、DeepMind、香港大学联合研究的对比学习生成框架:A Contrastive Framework for Neural Text Generation。该工作针对开放式文本生成任务(Open-ended TextGeneration)提出了一个新的训练策略(SimCTG)以及解码算法(contrastive search)。作者在来自多语言的不同任务以及实际工业场景中进行了大量的自动及人工评测。实验结果表明该方法显著提升了文本生成模型的效果,并在中文对话任务上达到了接近人类写作文本的流利性、丰富性和相关性。同时,在Github开源项目中作者还详细展示了如何在中文,英文,日文,韩文等语言生成模型上使用该方法的结果。
贡献
最近,伴随着以GPT-2为代表的自回归预训练语言模型的提出,开放域文本生成不再是五至十年前遥不可及的镜花水月,而成为了学术界和工业界竞相挑战的热点问题。通过大数据训练的预训练语言模型,能根据上文预测下一个词的概率分布,并通过一系列解码方法进行开放域文本生成。。然后,许多研究也发现,目前以GPT-2为代表的预训练语言模型在inference解码阶段通常会遇到比较严重的text degeneration问题(一系列使生成结果不自然的问题的统称,如重复、逻辑混乱、实体名错误等)。如图2所示,在用300G高质量中文文本训练的GPT-2模型上,无论是确定性解码方法贪婪搜索(greedy search)和集束搜索(beam search),还是目前在文本生成任务中展示出不错效果的采样方法(nucleus samplingHoltzmanet al., 2020),都会出现或多或少的重复和逻辑混乱现象,使生成结果变得不自然。

图2:不同解码方法下的GPT2生成结果
在本文中,作者们通过分析,推理出token表示空间的各异性是导致生成模型degeneration问题产生的原因,即token的表示聚集在表示空间的一部分狭窄的子集中,如下图所示:
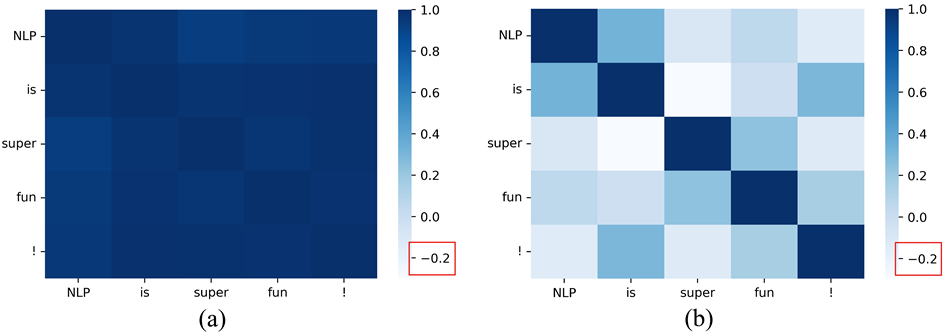
图3:token表示空间: (a) GPT-2; (b) SimCTG
可以发现,在"NLP is super fun!" 这个句子中,五个单词的表示相似性非常高。换句话说,增加或删除一个词对于句子的语义改变是比较小的。在推理阶段,相似的表示往往会导致模型预测出相似的概率分布,从而解码出重复的token序列。针对这一问题,作者提出了对比训练方法SimCTG和对比解码方法contrastive search来解决这一问题。
方法
SimCTG
SimCTG在传统语言模型训练的损失基础上添加了一项对比损失函数来校准token的表示空间,使同一句子中不同token的表示差异性尽量大,从而缓解各向异性的表示问题:
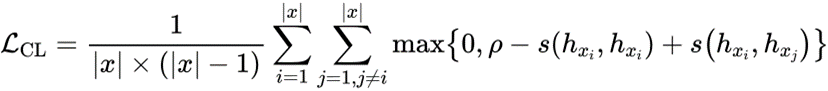
其中token表示之间的余弦相似度如下所示:
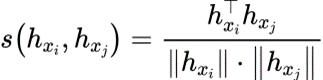
最终训练生成模型的损失函数如下所示:
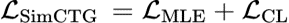
Contrastivesearch解码方法
在解码阶段,通过使用“degeneration penalty”来从候选token中选择最合适的token输出,从而避免了生成模型解码的degeneration问题。如下公式所示:
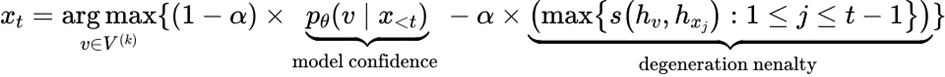
其中degenerationpenalty项计算了候选token和之前token表示之间的余弦相似度的最大值。α参数用来平衡两个分数之间的重要性,当α趋于0时,contrastive search退化为greedy search解码方法。虽然contrastive search解码方法需要对 k 个候选token进行重新的打分,但是通过简单的 cache 技巧,即可以显著提升contrastive search的推理效率。
虽然整体上用户需要先使用SimCTG训练,而后在推理阶段使用contrastive search。不过值得注意的是,在中文文本生成中,作者观察到即使不经过SimCTG的训练,直接使用contrastive search也能够取得非常好的效果,这进一步说明了作者提出的contrastive search解码方法具有通用性。
实验
作者选择GPT-2作为实验对比的基础模型,并考虑以下两个strong baseline: (1) 使用MLE损失优化的GPT-2模型;(2)使用unlikelihood训练损失优化的GPT-2模型。在解码方法上,作者把contrastive search解码方法与greedy search和beam search等确定性解码方法,以及目前性能最好的nucleus sampling解码方法进行了对比。为了全面评测模型和解码方法的效果,本文在wikitext-103语料上进行了试验,从三个不同的角度公平地对比不同模型和解码方法之间的优劣:(1)语言模型质量评估;(2)生成样本质量评估;(3)人工评估。
语言模型(languagemodeling) 质量以及生成质量的自动评测如下所示
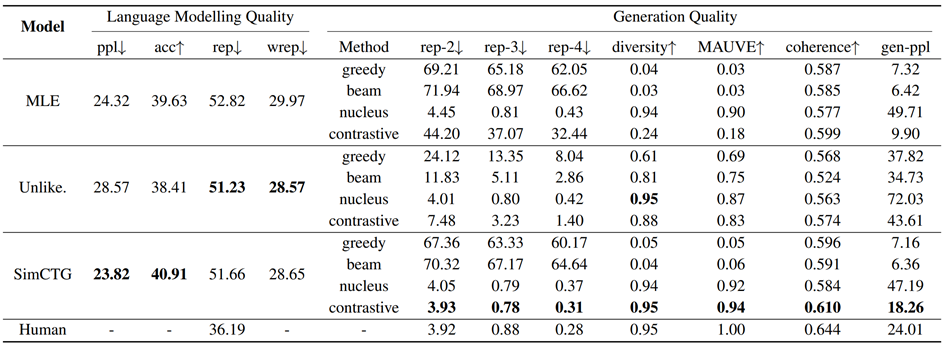
图4:语言模型和生成质量实验结果
通过语言模型质量的评估(图4左边),可以发现用SimCTG方法训练的模型的ppl和acc分数显著好于两个基线模型:用最大似然估计(MLE)和非似然度估计(Unlikelihood Training)方法训练的模型,这验证了作者们在前文的假设:通过校准GPT-2模型的表示空间可以提升语言模型的性能,另外,虽然基于非似然度估计方法训练的模型的rep和wrep分数略好于SimCTG,但是其语言模型的性能相对SimCTG和MLE会差很多。
在生成质量的评估中(图4右边),SimCTG+contrastive search的组合方法在各项指标上均取得了最优的性能。不使用SimCTG单独使用contrastive search解码方法也有不错的效果,不过依然弱于目前最好的nucleus采样方法,这也进一步验证了SimCTG的必要性。
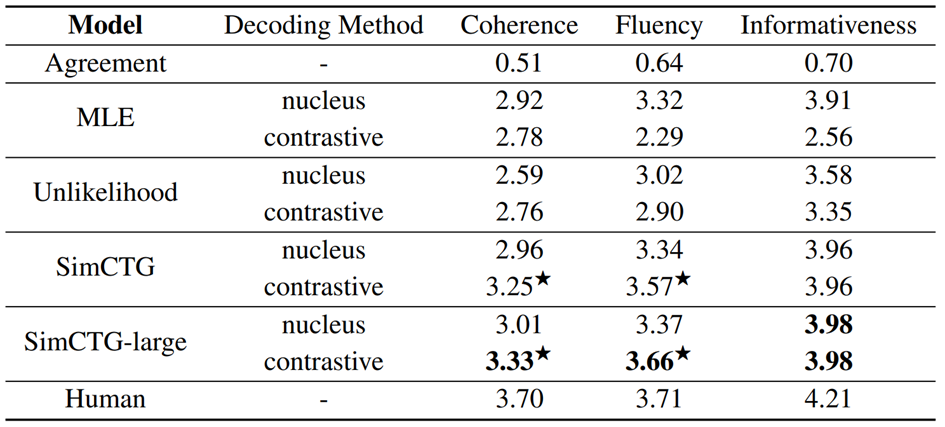
图5:开放域文档生成人工评价结果
在人工评价中,作者惊讶地发现,SimCTG + contrastive search采样方法在相关性、流利性和信息丰富度上,均远超目前最好的方法nucleus sampling,并且其流利度已经接近人类水平。另外,在MLE和Unlikelihood模型上直接使用contrastive search并不能带来性能增益,这点与自动评测的结论一致。
为了验证本文方法的通用性,作者进一步在开放域对话系统上进一步的测试。在这个实验中,模型需要根据一段对话历史生成下一句的对话内容,即在LCCC中文对话数据集上进行测试,在DailyDialog数据集上进行英文测试。
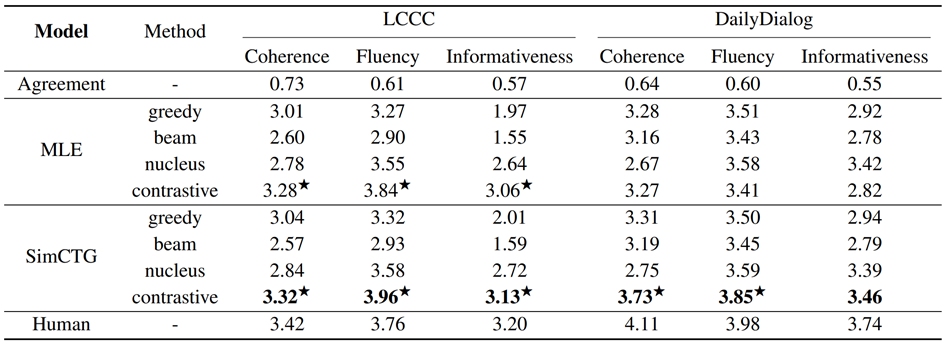
如上所示,可以得出以下几个结论:(1)SimCTG+contrastive search方法在开放域对话数据集上取得了最佳的效果,其中值得注意的是,LCCC数据集上SimCTG + contrastive search方法的流利性甚至超过人类水平;(2)此外,在中文上,即使没有经过SimCTG方法的训练,单独使用contrastive search依然可以显著提高了MLE模型的生成质量,这证明了contrastive search作为一种更先进的解码方法在对话任务上的有效性和通用性。

如上图所示,可以观察到集束搜索生成的结果质量比较低,缺乏多样性和连贯性;虽然nucleus方法生成的文本偶尔流利性比较好,但是因为随机采样的缘故,其生成的文本和容易出现和前文矛盾和不一致的表述。综合对比下,作者提出的contrastive search 方法生成的文本无论是多样性,连贯性还是和前文的一致性都显著优于其他的baseline。
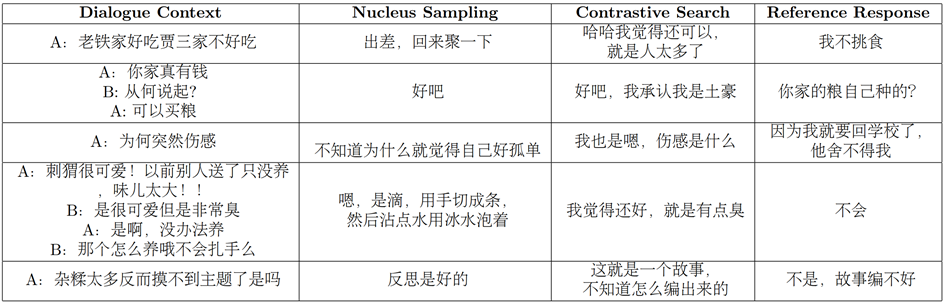
上图是几个开放域对话生成的例子,可以观察到生成的样本的质量和参考样本的质量非常接近,甚至有一些效果超过参考回复。
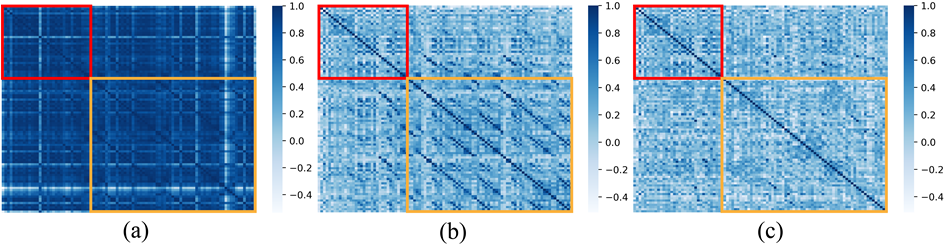
为了更清晰的理解contrastive search的作用,图10中作者展示了不同方法的token相似度的热力图。其中红色框表示Prefix的相似度矩阵,黄色框表示生成文本的相似度矩阵。可以发现,MLE+beamsearch的热力图中token相似度普遍极高,这说明经过MLE训练的模型生成的token表示很难进行区分,极其容易导致出现degeneration的问题;虽然将模型更换为SimCTG之后(图b),其相似度矩阵变得稀疏和可区分,degeneration的问题依然存在(有规律的斜线)。最终作者发现,使用SimCTG和contrastive search生成的文本不仅稀疏可区分,其生成文本并没有出现有规律的degeneration问题,黄色框和红色框的热力图矩阵情况是比较一致的,说明SimCTG+contrastivesearch生成的文本更接近人类真实文本。
参考
Su Y, Lan T, Wang Y, et al. A Contrastive Framework for Neural Text Generation[J]. arXiv preprint arXiv:2202.06417, 2022.
https://effidit.qq.com/
https://mp.weixin.qq.com/s/NW2wHVwdcQG_Aq6cYB4BsA
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢