标题:NVIDIA|Reducing Activation Recomputation in Large Transformer Models(减少大型变换器模型中的激活重新计算)
作者:Vijay Korthikanti, Jared Casper, Bryan Catanzaro等
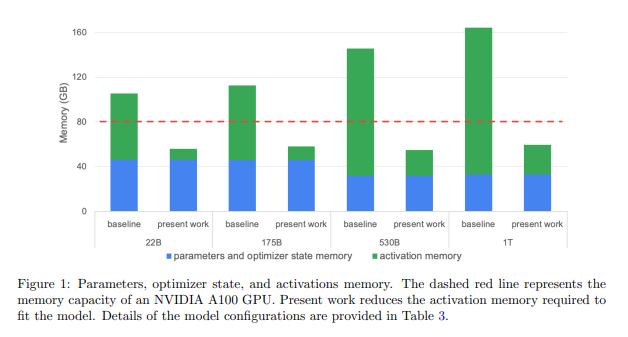
简介:训练大型变换器模型是现代人工智能研究的重要工作。在本文中,作者展示了如何显著加速大型变压器的训练,通过减少激活重新计算来建模。激活重新计算通常用于解决内存容量限制。它们不是存储用于反向传播的激活,而是传统上是重新计算的,这样可以节省内存,但会增加冗余计算。在这项工作中,作者显示大部分冗余计算是不必要的,因为作者可以从其他环节减少内存消耗。作者提出了两种新颖但非常简单的技术:序列并行性和选择性激活重新计算。结合张量并行性,这些技术几乎消除了重新计算激活的需要。作者评估在高达一万亿个参数的规模语言模型上的方法,并表明作者的方法通过以下方式减少了5×激活内存,同时将激活重新计算的执行时间开销降低 90% 以上。例如,在 2240 个 NVIDIA A100 GPU 上训练 530B 参数 GPT-3 样式模型时,作者使用重新计算实现了 54.2% 的FLOPS利用率,比作者实现的 42.1% 快 29%。
论文下载:https://arxiv.org/pdf/2205.05198v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢