
作者:Yong Dai, Duyu Tang, Liangxin Liu,等
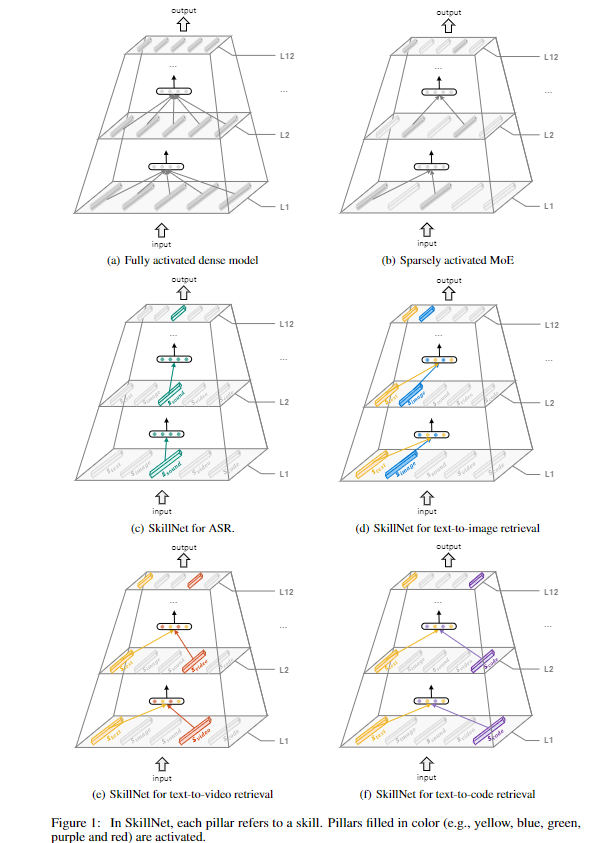
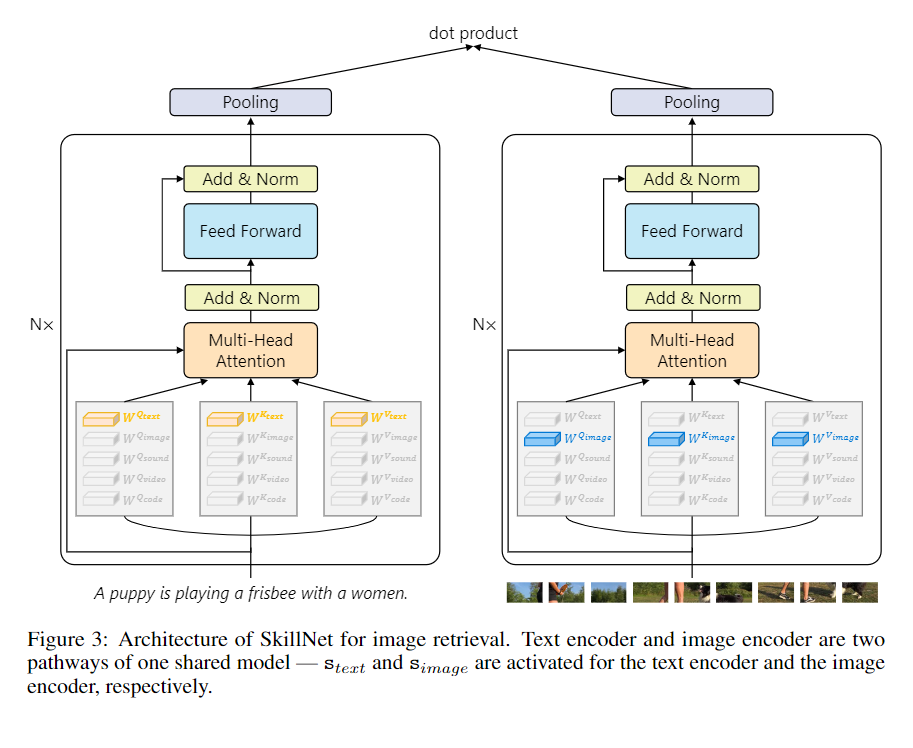
简介:人们通过多种感官感知世界(例如,通过听到声音、阅读文字和看到物体)。然而,大多数现有的人工智能系统只处理一个单独的模态。本文提出了一种方法,该方法擅长使用单个模型处理多种信息模式。在作者的SkillNet模型中,参数的不同部分专门用于处理不同的模态。与总是激活所有模型参数的传统密集模型不同,作者的模型稀疏地激活与任务相关的部分参数。这样的模型设计使 SkillNet 能够以更可解释的方式学习技能。作者为五种模式开发作者的模型,包括文本、图像、声音、视频和代码。结果表明,SkillNet 的性能与五种特定于模态的微调模型相当。此外,作者的模型支持以相同的稀疏激活方式进行自我监督预训练,从而为不同的模态提供更好的初始化参数。作者发现预训练显着提高了 SkillNet 在五种模态上的性能,与特定模态预训练的基线相当甚至更好。在中文文本到图像的检索任务上,作者的最终系统比现有的领先系统(包括 WukongViT-B和文澜2.0)实现了更高的准确度,同时使用更少的激活参数。
论文下载:https://arxiv.org/pdf/2205.06126
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢