
作者:Nishant Subramani , Nivedita Suresh , Matthew E. Peters
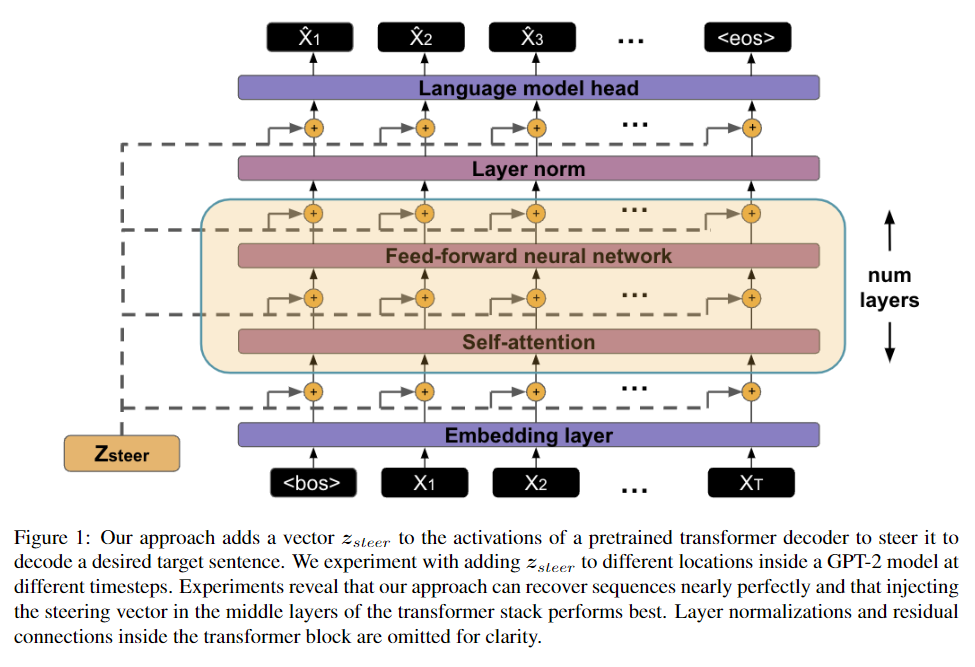
简介:先前关于可控文本生成的工作集中在学习如何通过可训练的解码、智能提示设计或基于期望目标的微调来控制语言模型。作者假设引导模型生成目标句子所需的信息已经在模型中编码。因此,作者完全探索了一种不同的方法:直接从预训练的语言模型解码器中提取潜在向量,无需微调。实验表明:存在转向向量,当添加到语言模型的隐藏状态时,可以为来自各种领域的英语句子生成几乎完美的目标句子。作者展示了向量算法可用于 Yelp 情绪基准上的无监督情绪转移,性能可与为此任务量身定制的模型相媲美。作者发现,在文本相似度基准STS-B上评估时,转向向量之间的距离反映了句子相似度,优于模型的池化隐藏状态。最后,作者对转向向量的内在特性进行了分析。总之,作者的结果表明,冻结的语言模型可以通过其潜在的转向空间得到有效控制。

论文下载:https://arxiv.org/pdf/2205.05124
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢