
【标题】A State-Distribution Matching Approach to Non-Episodic Reinforcement Learning
【作者团队】Archit Sharma, Rehaan Ahmad, Chelsea Finn
【发表日期】2022.5.11
【论文链接】https://arxiv.org/pdf/2205.05212.pdf
【DEMO链接】https://sites.google.com/view/medal-arl/home
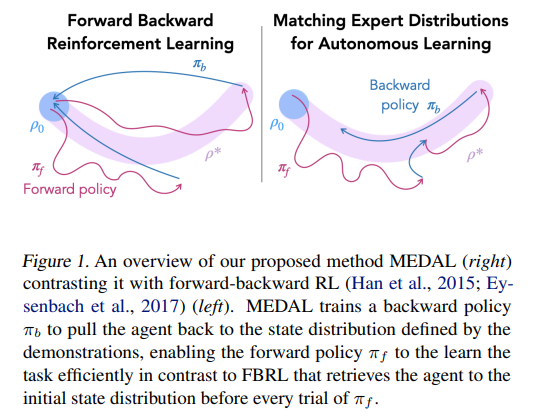
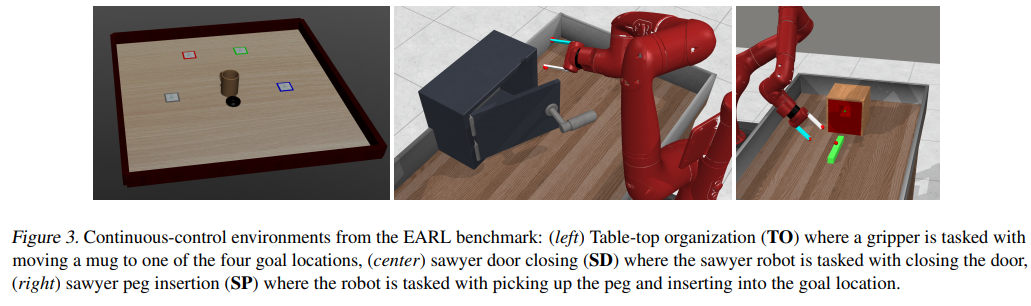
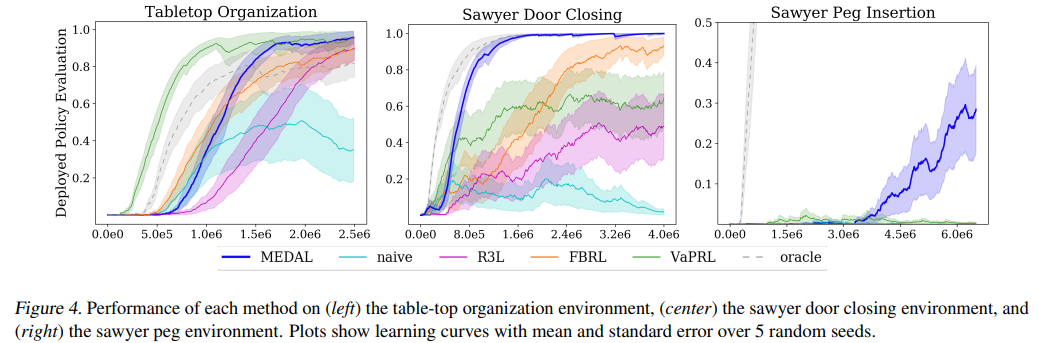
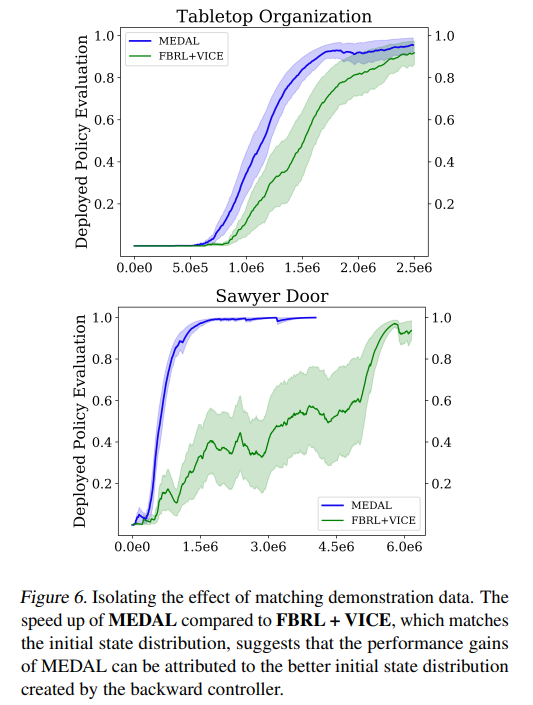
【推荐理由】虽然强化学习 (RL) 提供了一个通过反复试验进行学习的框架,但将 RL 算法转化为现实世界仍然具有挑战性。现实世界应用的主要障碍来自于在每次试验后重新设置环境的情景设置中的算法开发,这与人类和机器人等具体化代理所遇到的现实世界的连续性和非情景性形成对比。先前的研究考虑了一种交替方法,其中前向策略学习解决任务,反向策略学习重置环境,但反向策略应该将智能体重置为什么初始状态分布?假设访问了一些演示,其提出了MEDAL新方法,以训练反向策略以匹配提供的演示中的状态分布。这使智能体接近与任务相关的状态,允许前向策略混合容易和困难的起始状态。实验表明,MEDAL 在 EARL 基准测试的三个稀疏奖励连续控制任务上匹配或优于先前的方法,在最难的任务上获得 40% 的收益,同时做出的假设比之前的工作更少。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢