
【标题】State Encoders in Reinforcement Learning for Recommendation: A Reproducibility Study
【作者团队】Jin Huang, Harrie Oosterhuis, Bunyamin Cetinkaya, Thijs Rood, Maarten de Rijke
【发表日期】2022.5.10
【论文链接】https://arxiv.org/pdf/2205.04797.pdf
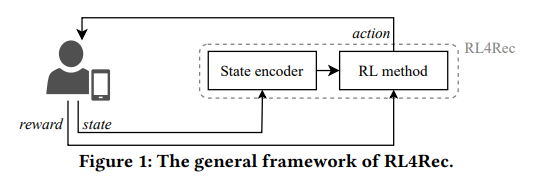
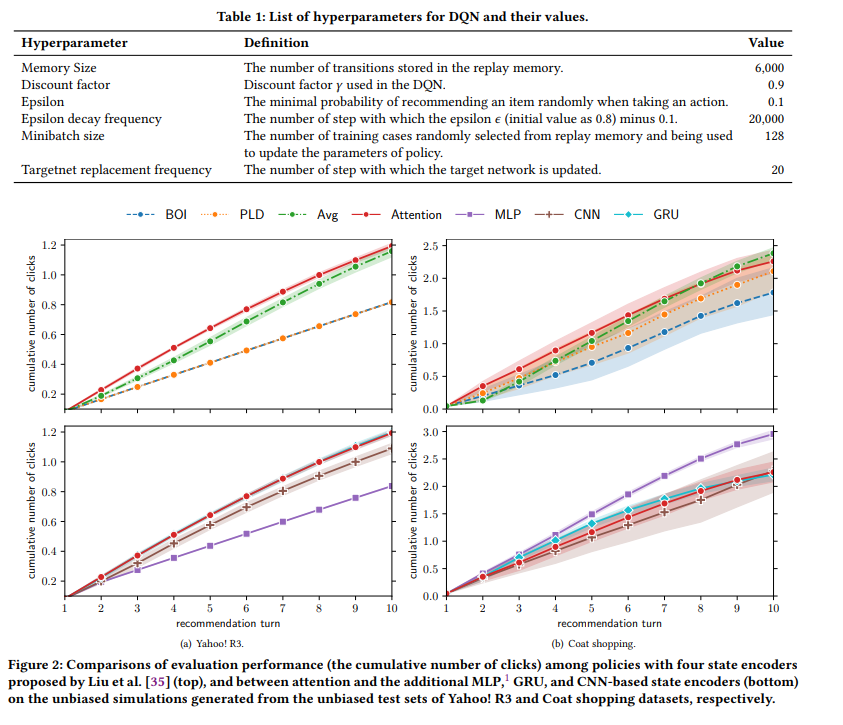
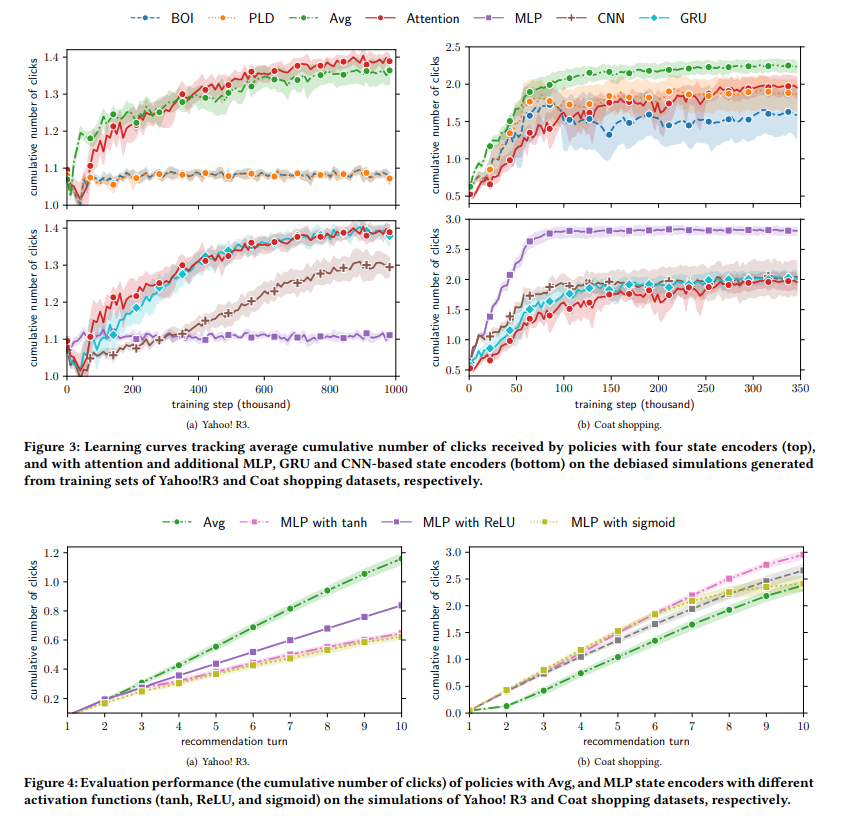
【推荐理由】推荐强化学习(RL4Rec)方法因能快速适应用户反馈而日益受到关注。典型的RL4Rec框架包括(1)一个状态编码器,用于对存储用户历史交互的状态进行编码;(2)一个RL方法,用于采取行动和观察奖励。现有的研究在基于真实世界记录的用户数据模拟用户反馈的环境中比较了四个状态编码器。基于注意力的状态编码器被认为是最佳选择,因为它达到了最优的性能。然而,这一发现仅限于actor-critic方法、四个状态编码器和评估模拟器,它们不会去偏向记录的用户数据。针对这些缺点,本文重现并扩展了现有的基于注意的状态编码器的比较(1)在公开的debiased RL4Rec SOFA模拟器中,与(2)不同的RL方法,(3)更多的状态编码器和(4)不同数据集的比较。重要的是,该实验结果表明,与更多的状态编码器相比,现有研究结果不能推广到从不同数据集和基于深度 Q 网络 (DQN) 的方法生成的debiased SOFA模拟器。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢