
VSR 的训练确实很费时间,本文提出多重网格训练和大型minibatch的办法来加速训练。客观的讲,空间周期变化对PSNR的影响相较时间周期要敏感一些,大型minibatch的方法固然可以加快速度但是使用中还需考虑显存问题。整体看来,时间周期加上对学习率的调整是个不错的加速选择。
详细信息如下:
论文名称:Accelerating the Training of Video Super-Resolution
作者单位:腾讯PCG ARC实验室
论文链接:https://arxiv.org/pdf/2205.05069.pdf
项目链接:https://github.com/TencentARC/Efficient-VSR-Training
看点
有效地训练有竞争力的VSR模型是一个具有挑战性的问题,它通常比训练对应的图像模型需要多出一个数量级的时间。现有的VSR方法通常从头到尾训练具有固定空间和时间大小的模型。固定大小通常设置为较大的值以获得良好的性能,但训练缓慢。
本文展示了逐步从小到大(空间/时间维度)训练视频模型的可能性。整个训练分为几个阶段,早期阶段的训练空间形状较小。每个阶段内时间大小从短到长变化。这种多重网格训练策略可以加速训练,因为大部分计算都是在较小的空间和较短的时间上进行的。为了进一步加速GPU并行化,本文还研究了在不损失精度的情况下进行大minibatch训练,使得各种VSR模型能够在不降低性能的情况下大幅提高训练速度(最高可达6.2倍)。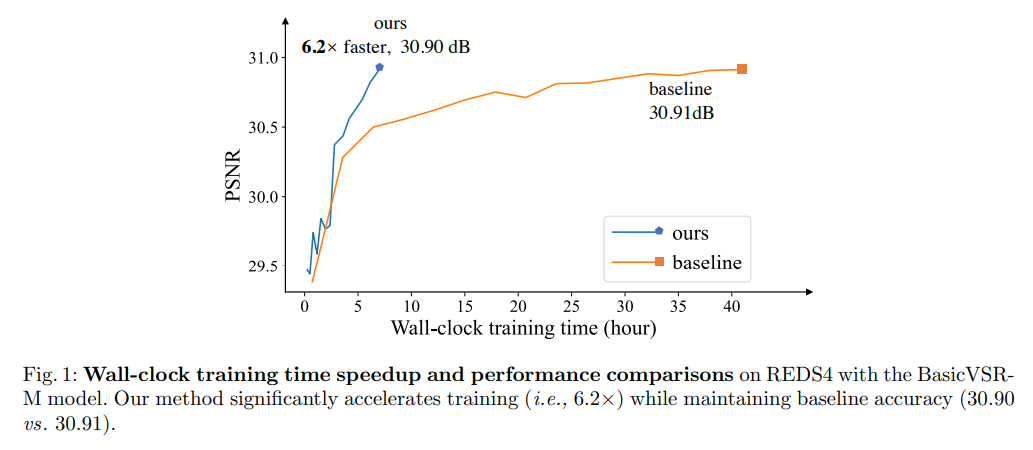
(这图怎么看着30.90dB比30.91dB还高)
实施细节
本文实现了BasicVSR-M、BasicVSR(M表示中等大小)来进行实验。它们的空间周期中使用的空间大小为均为32×32和64×64,时间周期为{7,11,15}。在32×32空间大小上训练的学习率从2e−4开始。学习率过大可能会导致EDVR-M的性能严重下降。此外在前5000次迭代中使用线性学习率预热来训练这些模型。
定量评估
当使用4×和2×较大的小批量训练BasicVSR-M和BasicVSR时,训练速度分别加快3.9倍和1.9倍。这种加速可以归因于大的小批量能够实现更好的GPU并行化。在不同的模型尺寸下,空间周期和时间周期都会给BasicVSR带来一致的加速比。
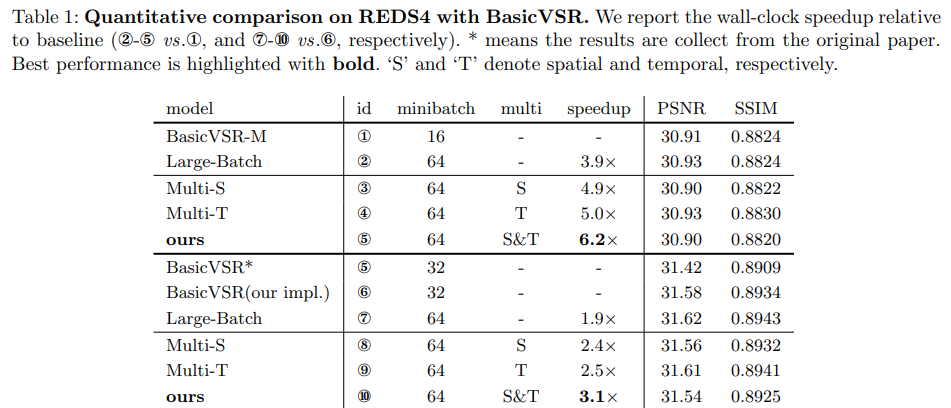
消融实验
如下图所示,直接增大minibatch会导致性能下降。然而,在进行学习率调整时,大型minibatch训练(带热身)的表现与基线相当。

下图研究了预热设置的影响。在没有预热的情况下直接应用线性调整会导致性能下降。这可能是因为在训练的早期,网络变化很快。在预热阶段的帮助下,大型minibatch训练的表现可以达到基线表现。
空间和时间周期的消融研究。
以同步方式简单地组合空间和时间周期中的大小(即,同时更改空间和时间大小)会导致性能下降。这可能是因为同时变化的空间/时间大小带来的巨大信息变化阻碍了学习过程。下图显示,以分层方式组合空间和时间周期可在不损失精度的情况下实现6.2倍的加速比。这些结果证明了我们多重网格设计的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢