
作者:Yu-Ming Shang, Heyan Huang, Xin Sun, Wei Wei, Xian-Ling Mao
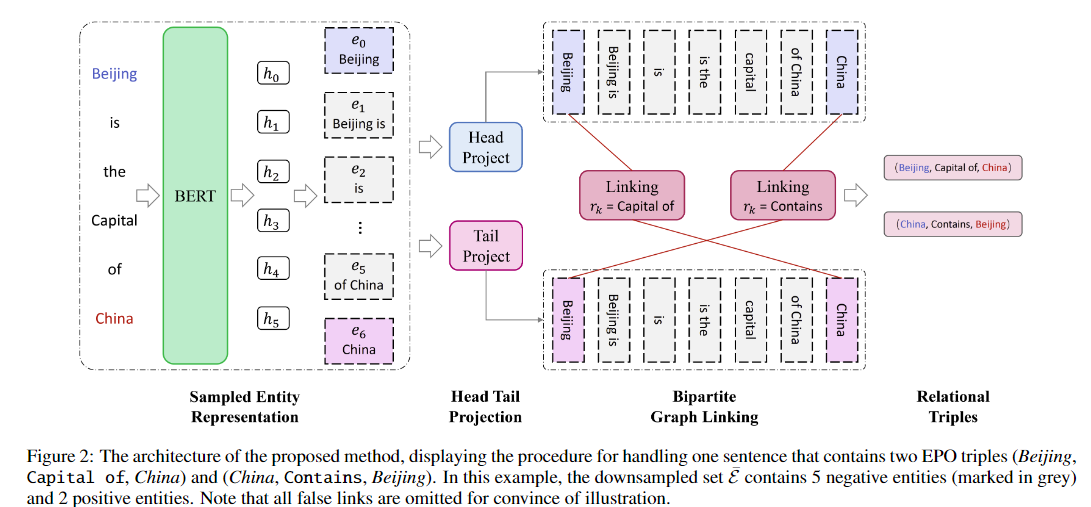
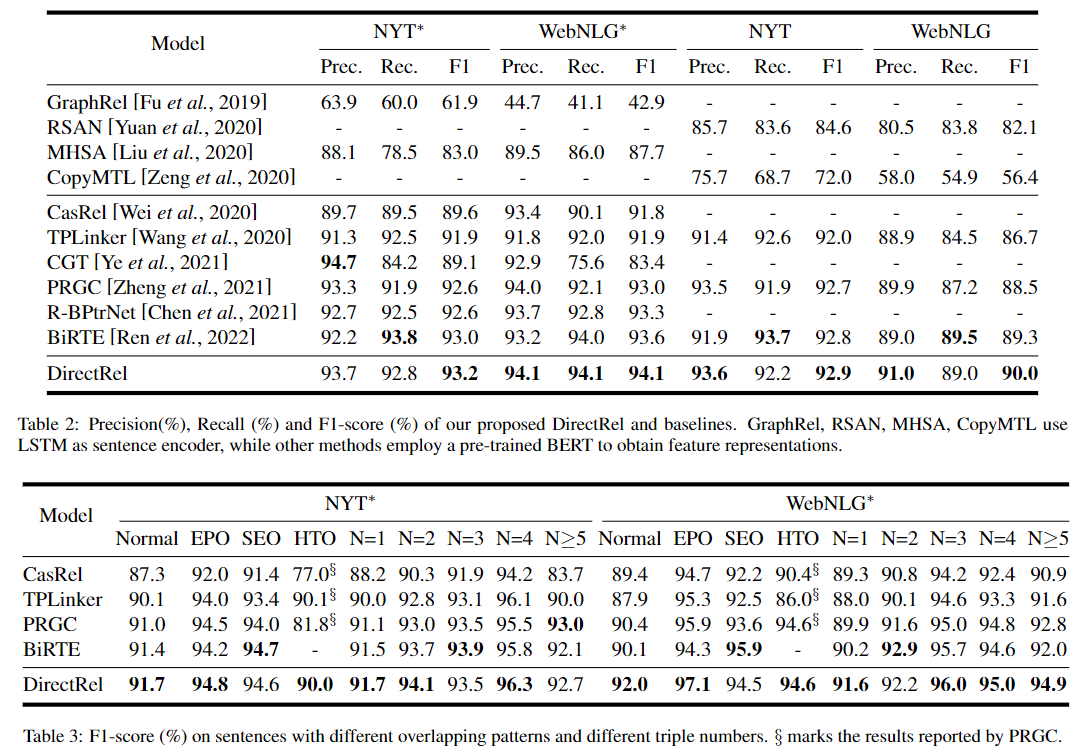
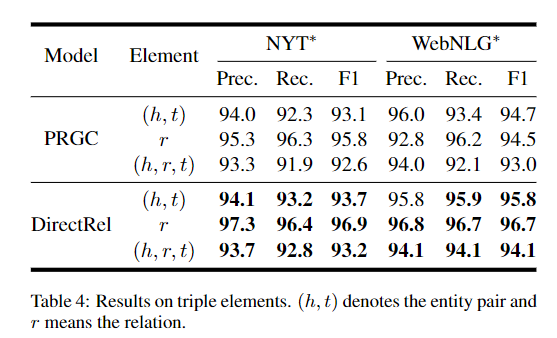
简介:基于预训练模型作为句子编码器、本文以全新的视角研究解决“关系抽取中的错误累积问题”、并提出SOTA模型。从非结构化文本中提取关系三元组是自然语言处理和知识图谱构建中的一项基本任务。现有方法通常包含两个基本步骤:(1)找到头尾实体的边界位置;(2) 连接特定标记以形成三元组。然而,几乎所有以前的方法都存在误差累积的问题,即步骤(1)中每个实体的边界识别误差将累积到最终形成的三元组中。为了解决这个问题,在本文中,作者引入了一个全新的视角来重新审视三元组提取任务,并提出了一个简单但有效的模型,名为 DirectRel。具体来说,所提出的模型首先通过枚举句子中的标记序列来生成候选实体,然后将三元组提取任务转化为“头→尾”双向图上的链接问题。通过这样做,只需一步即可直接提取所有三元组。在两个广泛使用的数据集上的广泛实验结果表明,所提出的模型比SOTA基线表现更好。
论文下载:https://arxiv.org/pdf/2205.05270
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢