标题:洛桑联邦理工学院、谷歌|SKILL: Structured Knowledge Infusion for Large Language Models(SKILL:大型语言模型的结构化知识注入)
作者:Fedor Moiseev, Zhe Dong, Enrique Alfonseca, Martin Jaggi
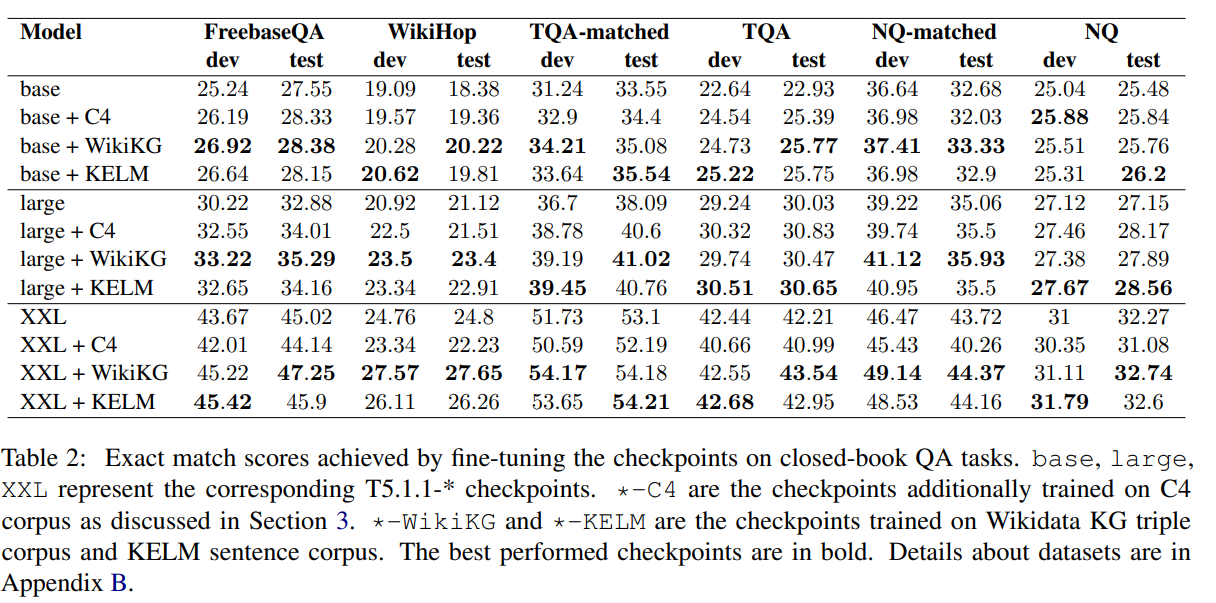
简介:本文介绍了融合知识图谱与文本的语言模型训练算法。大型语言模型(LLM)已经在自然语言任务的范围展示了人类水平的性能。然而在很大程度上,他们能否从结构化的知识中更好地内化知识和数据,如知识图谱或来自文本的数据,这在很大程度上是未被探索的。在这项工作中,作者提出了一种注入的方法,通过直接将结构化知识转化为LLM在知识图谱(GG)的事实三元组上训练T5模型。作者表明,使用作者的方法在维基数据KG上预训练的模型优于FreebaseQA、WikiHop、维基数据可问TriviaQA和NaturalQuestions上的T5基线。这在事实三元组比较上预训练模型与与包含相同知识的自然语言句子上的句子竞争。在较小尺寸的KG,WikiMovies上进行训练后,作者看到了在MetaQA任务的匹配分数基线上,与 T5 相比3倍精确度的改进。所提方法的优点是图谱和文本语料库训练数据知识之间不需要对齐。这使得作者的方法在处理大规模工业知识图谱时特别有用。
论文下载:https://arxiv.org/pdf/2205.08184v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢