
作者:Moniba Keymanesh, Adrian Benton, Mark Dredze
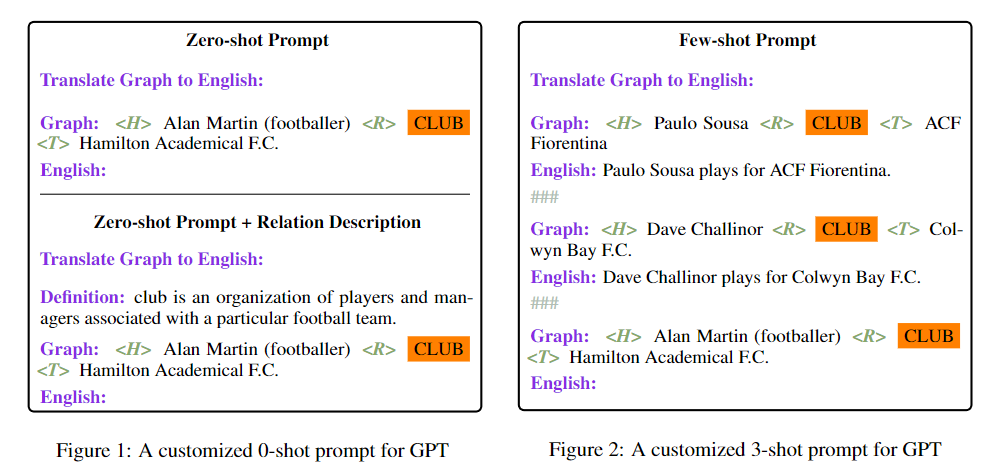
简介:本文研究数据到文本生成领域的预训练技术。在表达结构化事实或关系的自然语言描述之时,数据到文本的生成 (D2T):增加了结构化知识库的可访问性。先前的工作表明,在对大量特定于任务的训练数据进行微调后,预训练语言模型 (PLM) 在这项任务上表现非常出色。另一方面,虽然自回归 PLM 可以从一些任务示例中进行概括,但它们在 D2T 中的功效在很大程度上尚未得到探索。此外,作者对 PLM 在 D2T 上的限制了解不完整。在这项工作中,作者对 DART 多域 D2T 数据集上的微调和自回归 PLM 进行了实证研究。作者将它们的性能视为特定任务数据量以及这些数据如何被纳入模型的函数:零样本和少样本学习,以及模型权重的微调。再有,作者通过测量评估数据子集的性能来探索 PLM 的局限性:新颖的谓词和抽象的测试示例。为了提高这些子集的性能,作者研究了两种技术:在上下文中提供谓词描述,并根据源中反映的信息重新排列生成的候选者。最后,作者对模型错误进行了人工评估,并表明 D2T 生成任务将受益于具有更仔细的手动管理的数据集。
论文下载:https://arxiv.org/pdf/2205.11505
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢