
近日,阿里巴巴大淘宝技术多媒体算法团队与计算机视觉青年学者刘偲教授团队合作论文:《GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection》 被CVPR 2022接收。
本文在业界首次将大规模预训练模型的海量数据中蕴含的丰富信息知识迁移到人物交互关系检测(Human-Object Interaction Detection, HOI)任务,单模型刷新了通用(Regular)和零样本(Zero-Shot)双任务的SOTA指标。
论文链接:
https://arxiv.org/abs/2203.13954
HOI存在两个核心问题:人-物关联(human-object association)和关系理解(interaction understanding)。我们分别在这两个核心问题上设计方案,整体如图1所示。
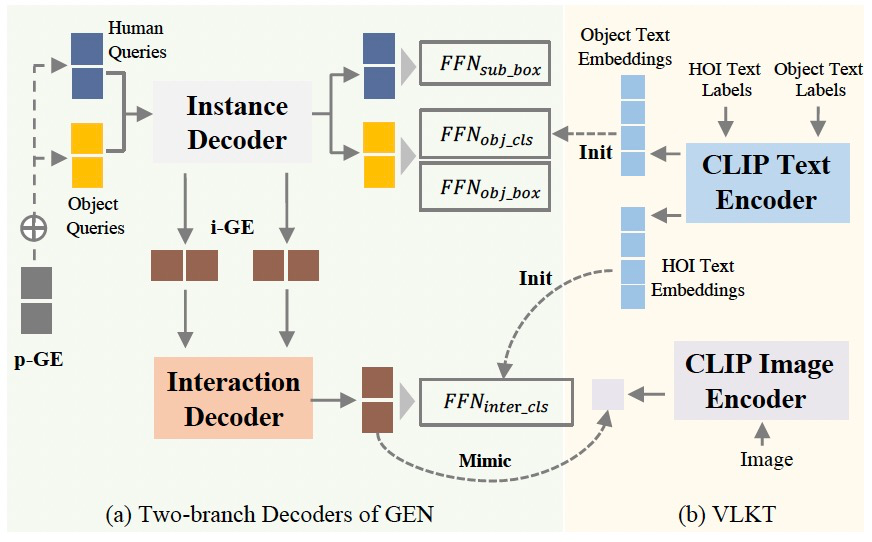
图 1:整体流程示意图
在人-物关联方面,传统两分支(two-branch)方法需要复杂且耗时的后处理,而单分支(single-branch)方法采用的统一特征造成了多任务的相互干扰。我们提出了GEN(Guided-Embedding Network)结构,通过引入位置引导(position Guided Embedding,p-GE)和实体引导(instance Guided Embedding, i-GE),实现了避免后处理的特征解耦的两分支结构。
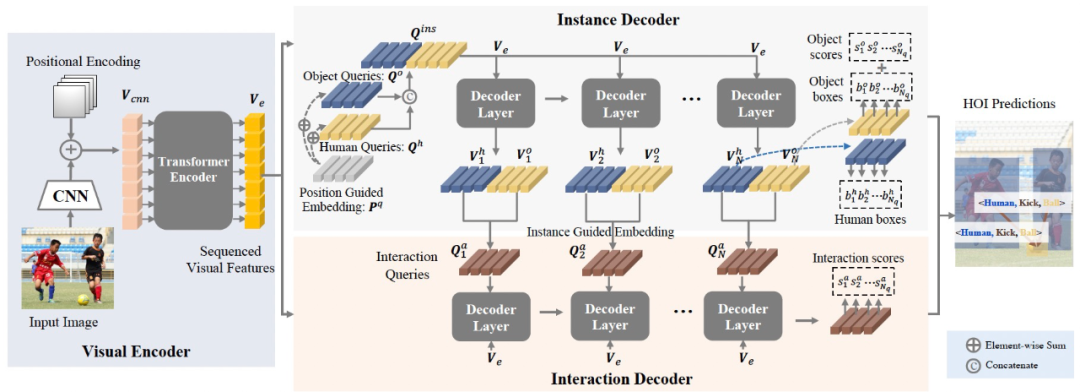
图2:Guided-Embedding Network (GEN)框架图
在关系理解方面,传统方法受数据长尾分布影响严重,也缺乏零样本(Zero-Shot)发现能力。我们设计了VLKT(Visual-Linguistic Knowledge Transfer)训练策略,通过迁移大规模图文数据预训练模型CLIP中蕴含的知识,增强对交互关系的理解,提升零样本理解能力。
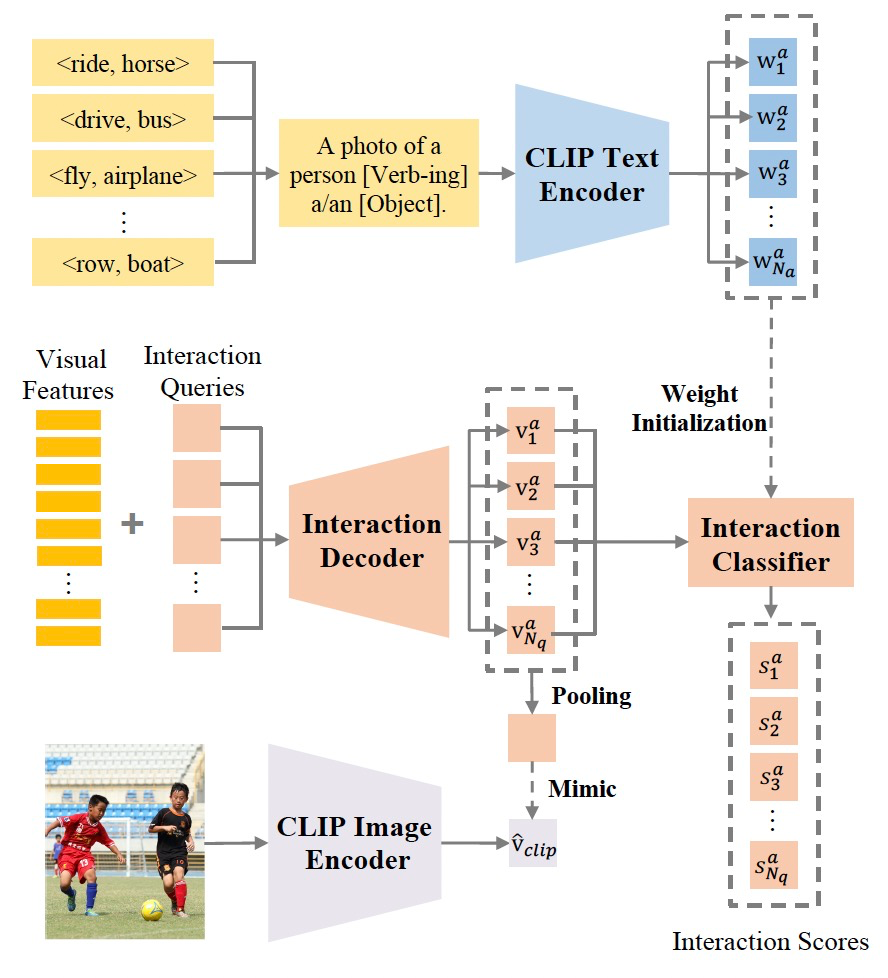
图3:用于解码器的Visual-Linguistic Knowledge Transfer (VLKT)框架图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢