标题:新加坡国立、南洋理工、华为|Deeper vs Wider: A Revisit of Transformer Configuration(更深与更宽:变换器配置的重新审视)
作者:Fuzhao Xue, Jianghai Chen,Yang You等
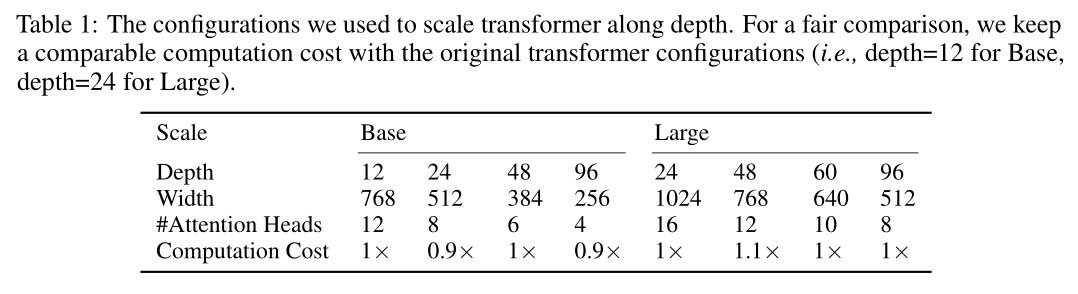
简介:本文研究了BERT与BEiT变换器模型的改进超参数。基于变换器的模型在许多任务上都取得了令人印象深刻的结果,尤其是视觉和语言任务。许多模型训练通常采用配置,例如,经常将基本模型设置为隐藏尺寸(即模型宽度)为768和变换器层(即模型深度)为 12。在本文中,作者重新审视这些常规配置,通过理论分析和实验评估,作者证明屏蔽的自动编码器可有效缓解过度平滑问题,在深度变换器训练中。基于这一发现,作者提出了Bamboo,使用更深更窄的变换器配置,用于训练屏蔽自动编码器。在ImageNet上,重新设计型号达到 87.1% 的第 1 名准确率,并优于 MAE 和 BEiT等 SoTA 模型。在语言任务上,在 GLUE 数据集上重新设计的模型优于默认的 BERT平均 1.1 分。
论文下载:https://arxiv.org/pdf/2205.10505.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢