【标题】Reinforcement Learning with Brain-Inspired Modulation can Improve Adaptation to Environmental Changes
【作者团队】Eric Chalmers, Artur Luczak
【发表日期】2022.5.19
【论文链接】https://arxiv.org/pdf/2205.09729.pdf
【Code链接】 https://github.com/echalmers/modulated_td_error
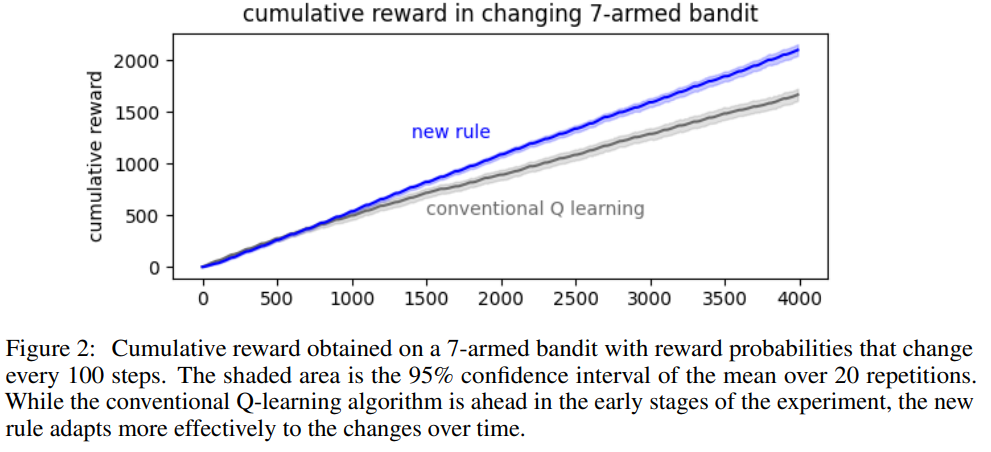
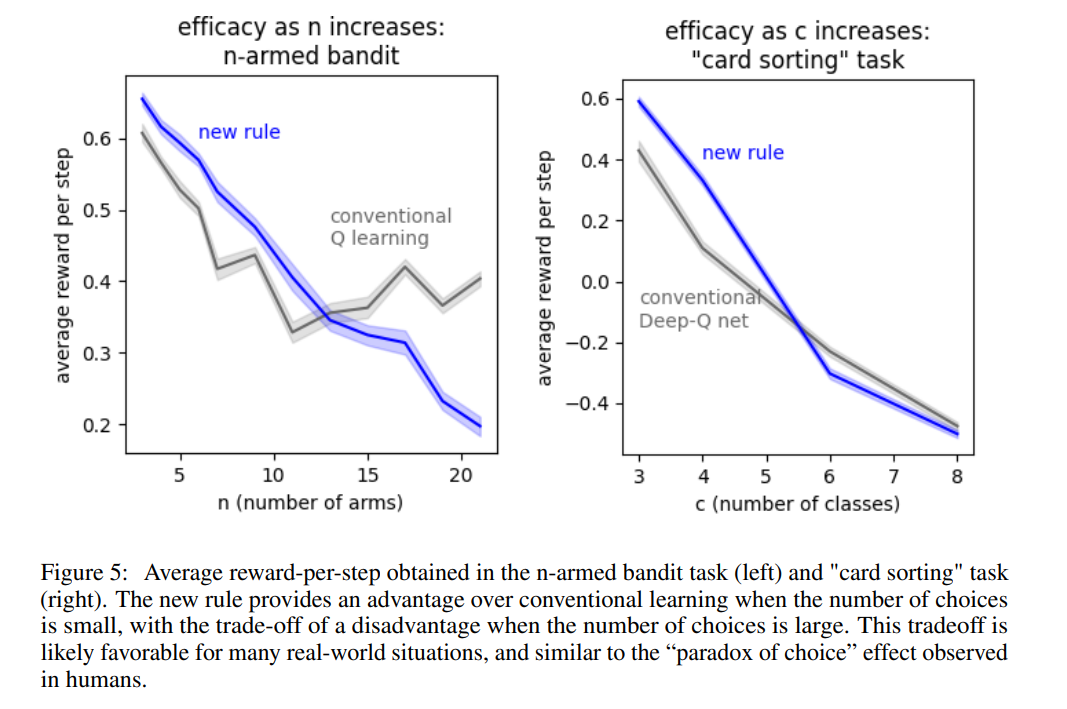
【推荐理由】强化学习 (RL) 的发展使算法能够在高度复杂但主要是静态的问题中取得令人印象深刻的性能。相比之下,生物学习似乎更重视适应不断变化的世界效率。本文以最近提出的神经元学习规则为基础,该规则假设每个神经元都可以通过预测自己的未来活动来优化其能量平衡。该假设导致神经元学习规则使用突触前输入来调节预测误差。类似的 RL 规则将使用动作概率来调节奖励预测误差。这种调节使智能体对负面体验更加敏感,并且在形成偏好时更加谨慎。通过将提出的规则嵌入到表格和深度 Q 网络 RL 算法中,并发现它在简单但高度动态的任务中优于传统算法。此外新规则包含了生物智能的核心原则;允许算法以类似人类的方式适应变化的重要组成部分。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢