
【标题】Data Valuation for Offline Reinforcement Learning
【作者团队】Amir Abolfazli, Gregory Palmer, Daniel Kudenko
【发表日期】2022.5.19
【论文链接】https://arxiv.org/pdf/2205.09550.pdf
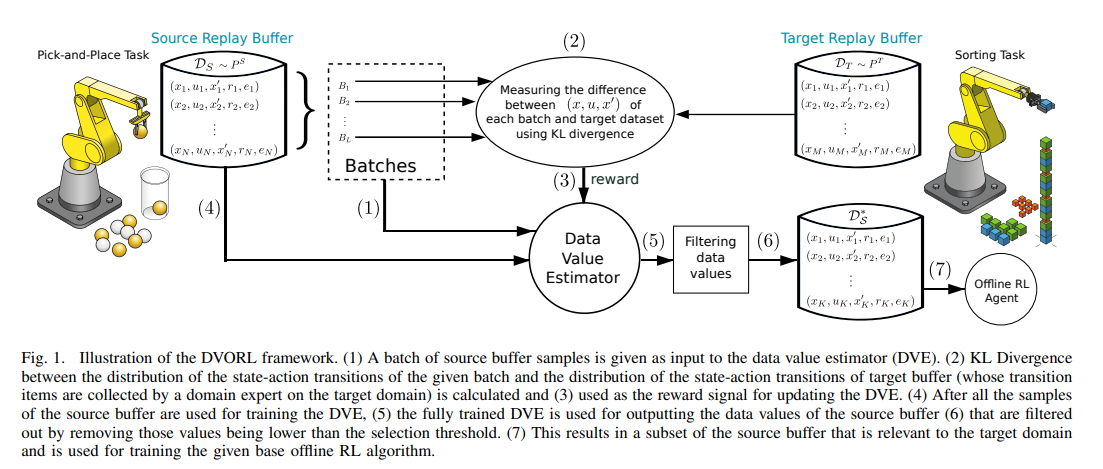
【推荐理由】深度强化学习 (DRL) 的成功取决于训练数据的可用性,这通常是通过大量环境交互获得的。随着数据市场的出现,内部构建数据集的替代方法是购买外部数据。然而,虽然最先进的离线强化学习方法已经显示出很大的前景,但它们目前依赖于精心构建的数据集,这些数据集与预期的目标域很好地对齐。这引发了关于在外部获取的数据上训练的离线强化学习代理的可迁移性和鲁棒性的问题。本文经验性地评估了当前最先进的离线强化学习方法在两个 MuJoCo 环境中应对源-目标域不匹配的能力,发现当前最先进的离线强化学习方法算法在目标域中表现不佳。为了解决此问题,其提出了离线强化学习(DVORL)的数据评估,它允许能够识别相关和高质量的转换,以提高离线强化学习算法学习的策略的性能和可迁移性。结果表明,该方法在两个 MuJoCo 环境中优于离线强化学习基线。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢