
【标题】Parallel bandit architecture based on laser chaos for reinforcement learning
【作者团队】Takashi Urushibara, Nicolas Chauvet, Satoshi Kochi, Satoshi Sunada, Kazutaka Kanno, Atsushi Uchida, Ryoichi Horisaki, Makoto Naruse
【发表日期】2022.5.19
【论文链接】https://arxiv.org/pdf/2205.09543.pdf
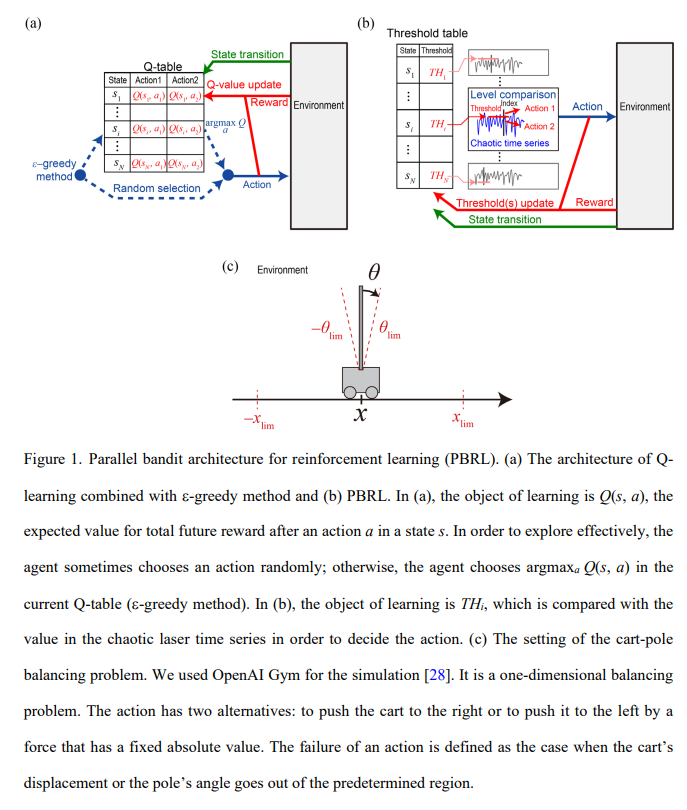
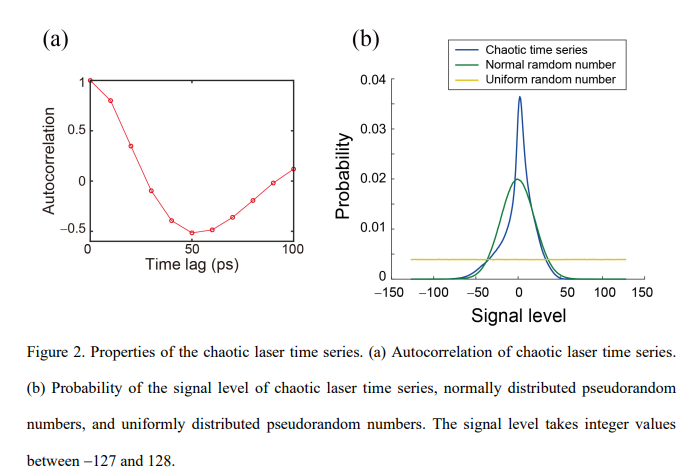
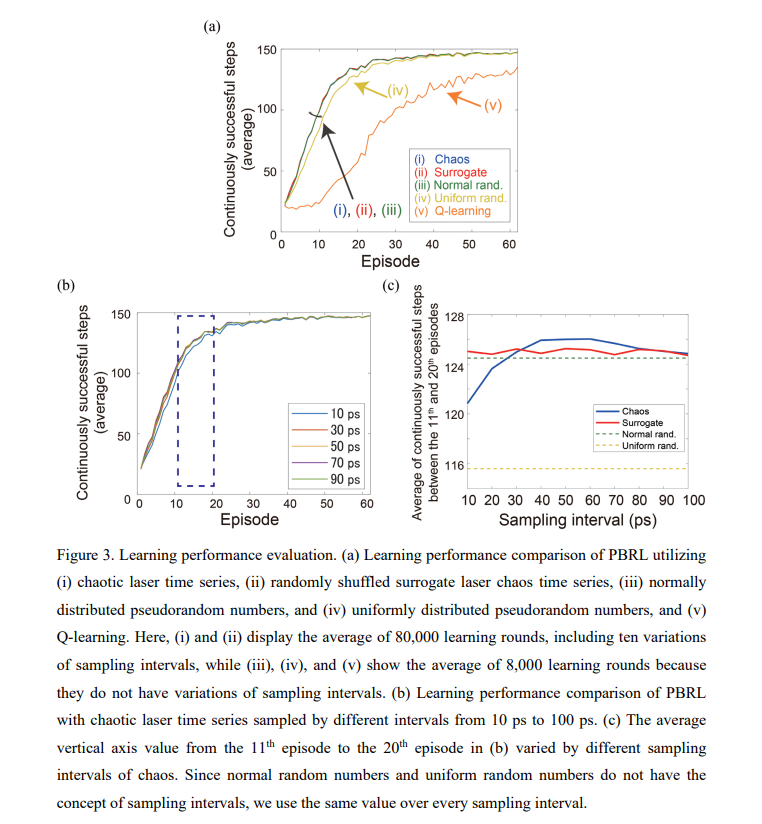
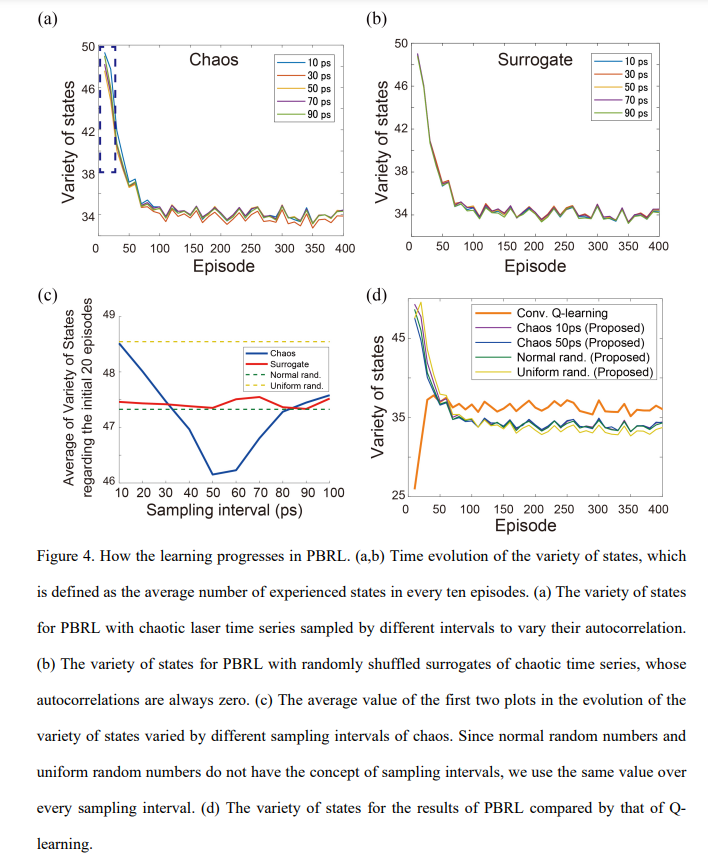
【推荐理由】通过光子学加速人工智能是活跃的研究领域,旨在利用光子的独特特性。强化学习是机器学习的重要分支,光子决策原理已经在多臂bandit问题上得到证明。然而,强化学习可能涉及大量状态,这与之前展示的bandit问题不同,后者的状态数量只有一个。本文组织了用于多状态强化学习的新架构,作为bandit问题的并行阵列,以便从光子决策者中受益,将其称为强化学习的并行赌博机架构或 PBRL。以cart-pole平衡问题为例,证明了 PBRL 在比 Q-learning 更少的时间步长内适应环境。此外,与激光混沌中固有的自相关提供积极影响的均匀分布的伪随机数相比,PBRL 在使用混沌激光时间序列时产生更快的适应。研究还发现,系统在学习阶段经历的各种状态在 PBRL 和 Q 学习之间表现出完全不同的特性。通过本研究获得的见解也有利于现有计算平台,而不仅仅是光子实现,通过PBRL算法和相关随机序列加速性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢