
【标题】Multicast Scheduling for Multi-Message over Multi-Channel: A Permutation-based Wolpertinger Deep Reinforcement Learning Method
【作者团队】Ran Li, Chuan Huang, Han Zhang, Shengpei Jiang
【发表日期】2022.5.19
【论文链接】https://arxiv.org/pdf/2205.095420.pdf
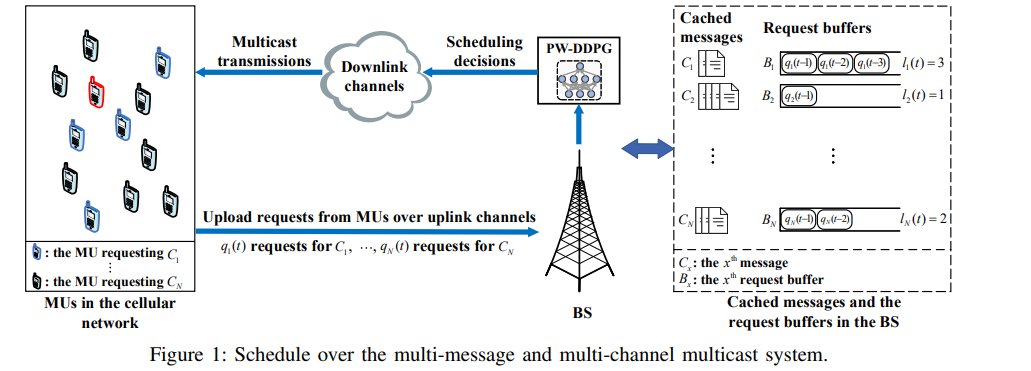
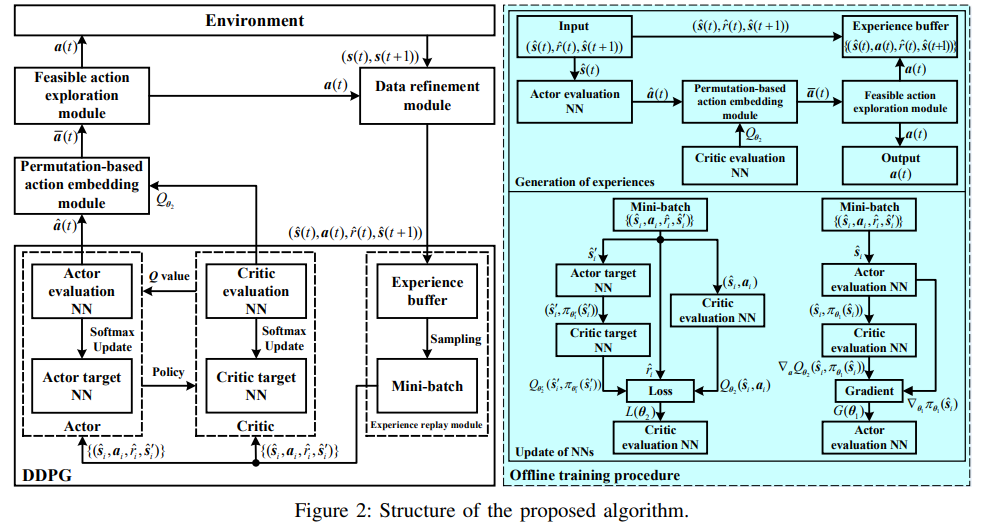
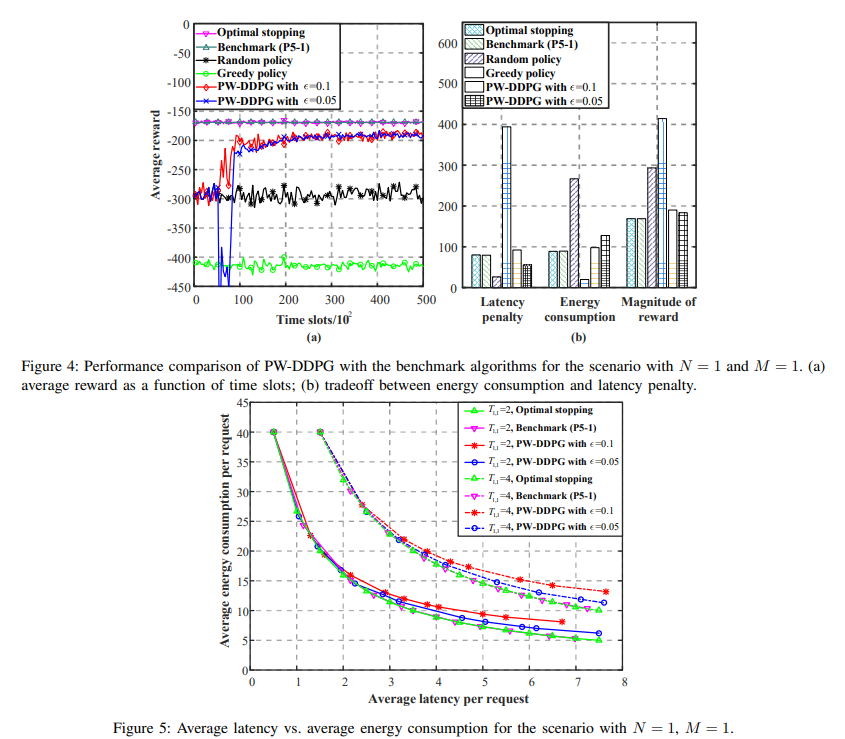
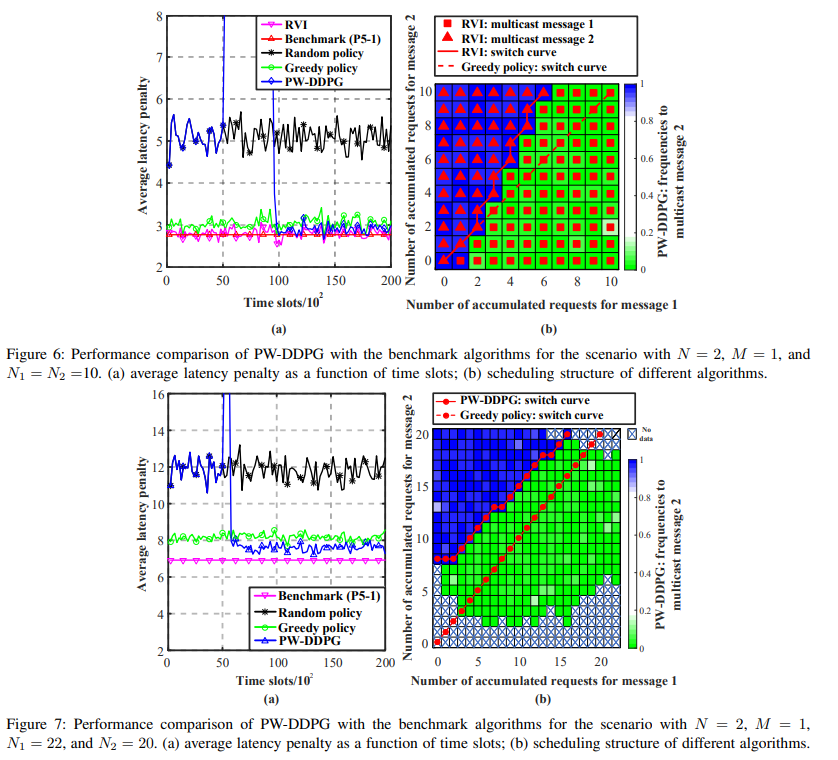
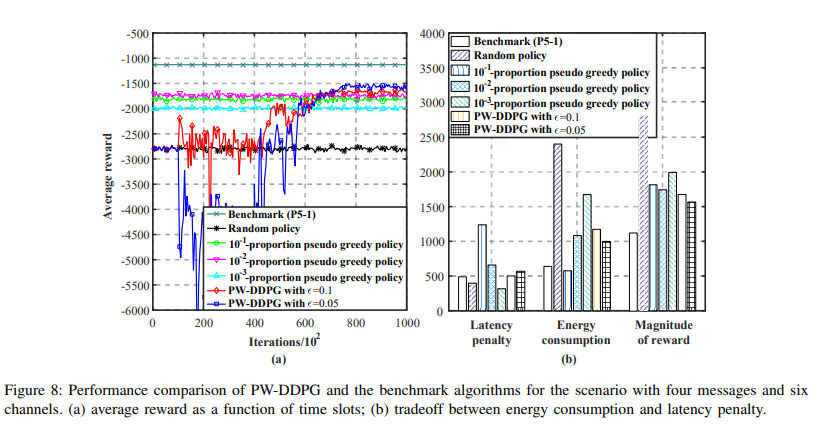
【推荐理由】多播是一种将公共消息从基站(BS)同时传输给多个移动用户(MU)的有效技术。将多信道多消息组播调度问题描述为一个具有大离散动作空间和多个时变约束的无限时域马尔可夫决策过程(MDP),该问题共同最小化了基站的能量消耗和服务来自MUs的异步请求的延迟,这在现有研究中未得到有效的解决。通过研究该MDP在平稳策略下的内在特征和改进奖励函数,首先将其简化为具有更小状态空间的等价形式。然后,提出了改进的深度强化学习(DRL)算法,即基于置换的Wolpertinger深度确定性策略梯度(PW-DDPG),以解决简化问题,PW-DDPG利用基于置换的动作嵌入模块来解决大型离散动作空间问题,并利用可行探索模块来处理时变约束。此外,作为基准,通过求解整数规划问题,导出了所考虑的MDP的上界。数值结果验证了该算法的性能接近于推导的基准。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢