
这是一个能用于视频模型的自监督预训练方法:掩码特征预测(MaskFeat)。

Masked Feature Prediction for Self-Supervised Visual Pre-TrainingMasked Feature Prediction for Vision Self-Supervised Pre-Training
https://arxiv.org/abs/2112.09133
简而言之,MaskFeat的ViT-B在ImageNet 1K上的准确率达到了84.0%,MViT-L在Kinetics-400上的准确率达到了86.7%,成功地超越了BEiT等方法。

一作Chen Wei是约翰·霍普金斯大学的计算机科学博士生,此前在北京大学获得了计算机科学学士学位。
并曾在FAIR、谷歌和华为诺亚方舟实验室实习,主要研究方向是视觉自监督学习。
HOG VS Pixel Colors
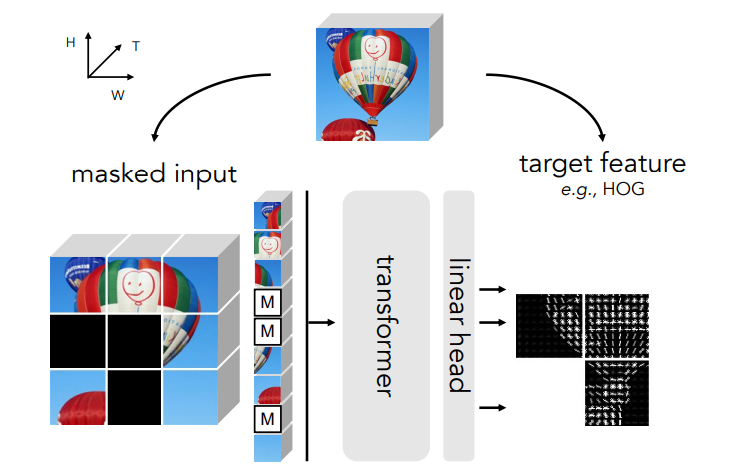
「Mask-and-Predict」总要有个可以「Predict」的特征来让模型学习到东西。 MaskFeat最核心的改变就是将MAE对图像像素(pixel)的直接预测,替换成对图像的方向梯度直方图(HOG)的预测。

图像HOG特征向量
说到HOG,这可不是什么新鲜玩意儿。

https://hal.inria.fr/file/index/docid/548512/filename/hog_cvpr2005.pdf
HOG是一种经典的图像特征提取算法,发表于2005年的CVPR,到现在已经收获了37000+的引用。
那为什么预测图像的HOG比直接预测像素更好呢?
像素作为预测目标,有一个潜在的缺点,那就是会让模型过度拟合局部统计数据(例如光照和对比度变化)和高频细节,而这些对于视觉内容的解释来说很可能并不是特别重要。
相反,方向梯度直方图(HOG)是描述局部子区域内梯度方向或边缘方向分布的特征描述符,通过简单的梯度滤波(即减去相邻像素)来计算每个像素的梯度大小和方向来实现的。

通过将局部梯度组织化和归一化,HOG对模糊问题更加稳健 HOG的特点是善于捕捉局部形状和外观,同时对几何变化不敏感,对光的变化也有不变性,计算引入的开销还很小,可以忽略不计。

这次,MaskFeat引入HOG,其实正是将手工特征与深度学习模型结合起来的一次尝试。
MaskFeat首先随机地mask输入序列的一部分,然后预测被mask区域的特征。

对未见过的验证图像的HOG预测
只不过,模型是通过预测给定masked input(左)的HOG特征(中间)来学习的,原始图像(右)并不用于预测。 方向梯度直方图(HOG)这个点子的加入使得MaskFeat模型更加简化,在性能和效率方面都有非常出色的表现。
在不使用额外的模型权重、监督和数据的情况下,MaskFeat预训练的MViT-L在Kinetics-400数据集上获得了86.7%的Top-1准确率。
这个成绩以5.2%的幅度领先此前的SOTA,也超过了使用如IN-21K和JFT-300M这些大规模图像数据集的方法。
此外,MaskFeat的准确率在Kinetics-600数据集上为88.3%,在Kinetics-700数据集上为80.4%,在AVA数据集上为38.8 mAP,而在SSv2数据集上为75.0%。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢