
转自知乎:唐工
不仅是多模态Transformer 模型,多模态(multi-modal)是所有模型的发展趋势。
多模态模型是迄今为止最先进的,因为它们可以接受多种不同的输入方式(例如语言、图像、语音、视频) ,并且在某些情况下产生不同的输出模态。
这是一个令人兴奋的方向,因为就像现实世界一样,有些事情在多模态数据中更容易学习(例如,阅读某些东西并观看演示,比仅仅阅读它更有用)。
例如,从描述性的句子或段落生成图像(XMC-GAN 模型),或用人类语言描述图像的视觉内容(SimVLM 模型)。
因此,图像和文本的配对可以帮助多语种检索任务(MURAL 模型),更好地理解如何配对文本和图像输入(CxC)可以为图像字幕任务产出更好的结果。
同样,对视觉和文本数据的协同训练,也有助于提高视觉分类任务的准确性(ALIGN 模型)和鲁棒性,而对图像、视频和音频任务的协同训练则提高了所有模态的泛化性能(PolyVit 模型)。
还有一些诱人的线索表明,自然语言可以用作图像操作的输入(TIM-GAN 模型 ),告诉机器人如何与世界互动(BC-Z 模型),控制其他软件系统,预示着用户界面开发方式的潜在变化。
这些模型处理的模态将包括语音、声音、图像、视频和语言,甚至可能扩展到结构化数据(TAPAS 模型)、知识图谱(KELM 模型)和时间序列数据(TFT 模型)。
XMC-GAN 模型:跨模态 GAN
XMC-GAN (Cross-Modal Contrastive Generative Adversarial Network)模型,旨在解决生成对抗性网络(GAN)在图像合成领域的两类问题:
- 难以处理长而模糊的描述;
- 易出现模式崩溃的问题。
XMC-GAN 模型,通过学习使图像和文本之间的互信息最大化,利用图像-文本和图像-图像之间的对比丢失(contrastive loss)来实现文本到图像的生成。这种方法有助于鉴别器(discriminator,试图判断图像是真实还是虚构的)学习更健壮和鉴别特征,因此 XMC-GAN 是不容易模式崩溃,即使一段式(one-stage)的训练。
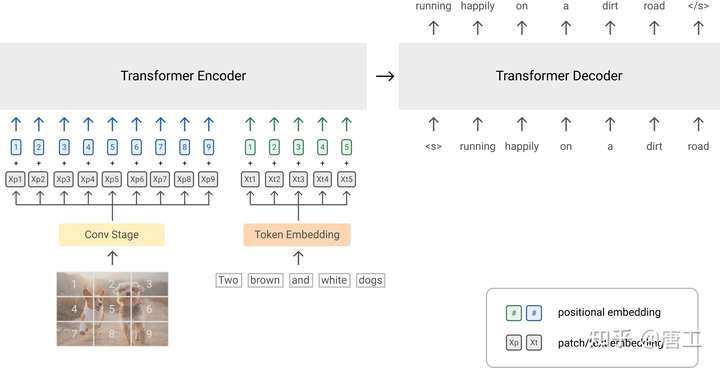
SimVLM 模型:简单可视化语言模型
SimVLM (Simple Visual Language Model)模型,旨在解决现有的视觉语言预训练(Viusal Language Pretraining,VLP)的导致可伸缩性较差的两类问题:
- 需要带注释的数据集;
- 需要时间来设计特定于任务的方法。
SimVLM 模型提出了一个简单而有效的 VLP,使用与语言建模类似的统一目标,对大量弱对齐的图像-文本对进行端到端的训练(即,与图像配对的文本不一定是对图像的精确描述)。
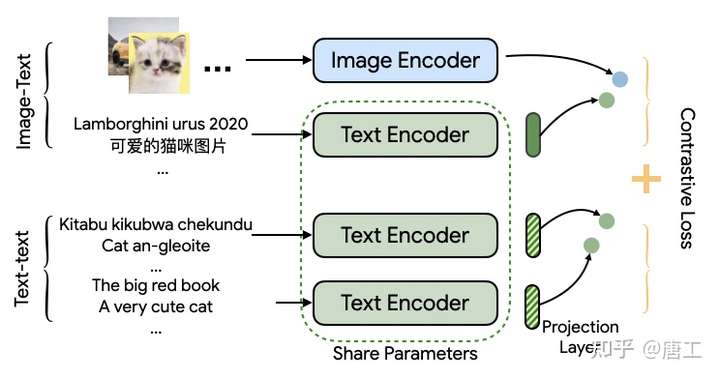
MURAL 模型:跨语言的多模态、多任务检索
MURAL (MUltimodal, MUltitask Representations Across Languages)模型,旨在解决图像-文本数据不匹配或数据不足的两类问题:
- 大多数语言中图像-文本对的数据的相距尺度甚大;
- 手工收集资源不足的语言的图文配对数据难度大。
MURAL 模型提出了一种图像-文本匹配的表示模型,该模型将多任务学习应用于图像-文本对,并结合涵盖100多种语言的翻译对。这项技术可以让用户使用图像来表达可能无法直接翻译成目标语言的单词。
MURAL 模型基于 ALIGN 的结构,但是以多任务的方式被使用。ALIGN 使用双编码器结构来绘制图像的表示和相关的文本描述,而 MURAL 则使用双编码器结构来达到同样的目的,同时通过结合翻译对将其扩展到多种语言。
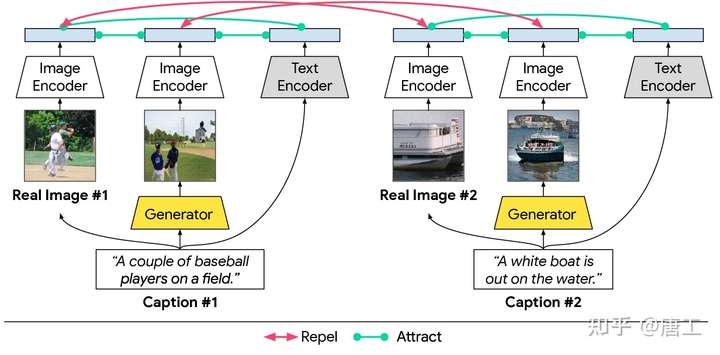
CxC 模型:图像和文本的语义相似性
CxC(Crisscrossed Captions)模型,旨在解决现有数据集由于跨模态关联局限性而导致的的问题:
- 图像不与其他图像配对,标题只与同一图像的其他标题配对,没有负面关联,也缺少正面的跨模态关联。
- 这就破坏了对于互通(inter-modality)模式学习(例如,将字幕与图像连接起来)如何影响内通(intra-modality)模式任务(将字幕与字幕或图像与图像连接起来)的研究。
CxC(Crisscrossed Captions)模型对图像-文本、文本-文本和图像-图像对进行了语义相似性评级。评分标准是基于语义文本相似度(Semantic Textual Similarity),一个现在广泛采用的衡量短文本之间的语义关系,被扩展到包括对图像的判别。

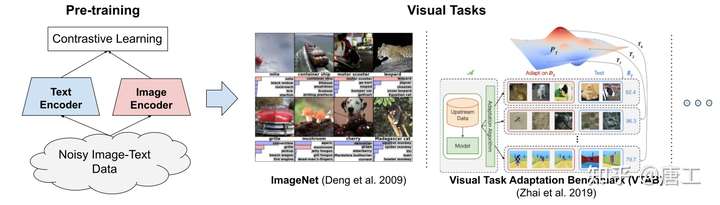
ALIGN 模型:在噪声文本监督下扩展视觉和视觉语言表征学习
ALIGN (A Large-scale ImaGe and Noisy-Text Embedding)模型,旨在解决当前视觉和视觉语言 SOTA 模型严重依赖于特定训练数据集的问题,这些训练数据集需要专家知识和广泛标签。
ALIGN 模型建议利用公开的图像替代文本数据来训练更大、SOTA 的视觉和视觉-语言模型,并采用了一个简单的双编码器结构,学习对齐图像和文本对的视觉和语言表示。
PolyVit 模型:图像、视频和音频的协同训练 ViT
PolyVit 模型,旨在训练一个能够处理多个模态和数据集的单 Transformer 模型,同时共享几乎所有可学习的参数。
PolyViT 模型,是一个在图像、音频和视频上训练的模型。在多个模态和任务上协同训练 PolyViT 可以生成一个参数效率更高的模型,并学习跨多个域泛化的表示形式。
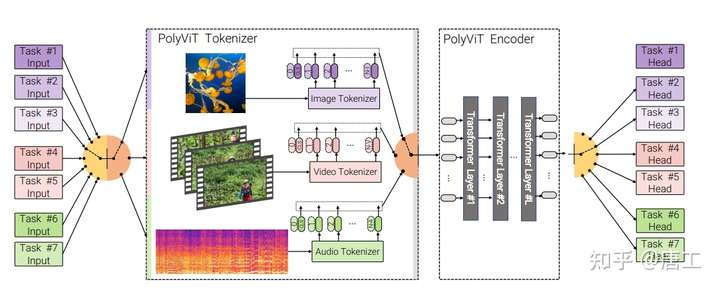
此外,协同训练的实现既简单又实用,因为不需要为每个数据集组合调整超参数,而是可以简单地从标准的单任务训练中调整这些超参数。
TIM-GAN 模型:通过文本指令操作图像
TIM-GAN(Text-Instructed Manipulation GAN)模型,关注文本引导的图像处理,将条件图像生成的输入从仅图像演变到多模态。
TIM-GAN 模型,提出了一种基于 GAN 的方法,允许用户使用复杂的文本指令来编辑具有多个对象的图像,以添加、删除或更改对象。
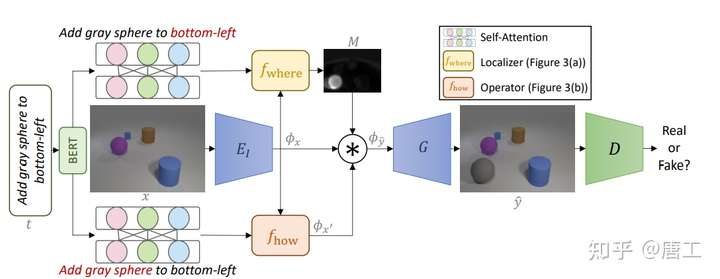
关键思想是将文本视为神经算子(neural operator)来局部修改图像特征。
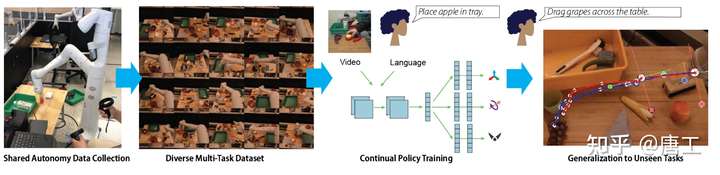
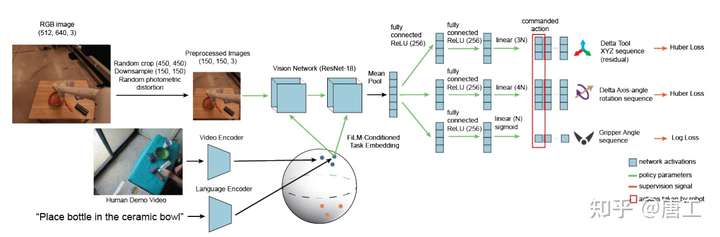
BC-Z 模型:基于机器人模仿学习的零样本任务泛化
BC-Z 模型,从模仿学习(imitation learning)的角度来探讨,旨在研究基于视觉的机器人操作系统,如何缩放和拓宽收集到的数据以提升泛化到新任务的能力。

BC-Z 模型,是一个互动式和灵活的模仿学习系统,可以从演示和干预中学习,并且可以以传达的任务的不同形式的信息为条件,包括预训练的自然语言嵌入或执行任务的人类视频。
TAPAS 模型:从更少的数据中学习推理结构化数据
TAPAS (Tabel Parsing)模型,旨在将自然语言推理的模型应用于结构化数据,将表格中的内容精确地总结和呈现给用户。
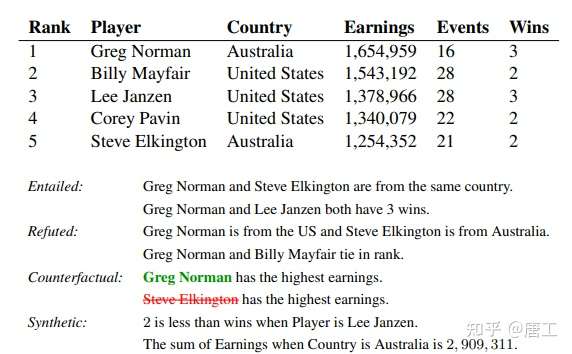
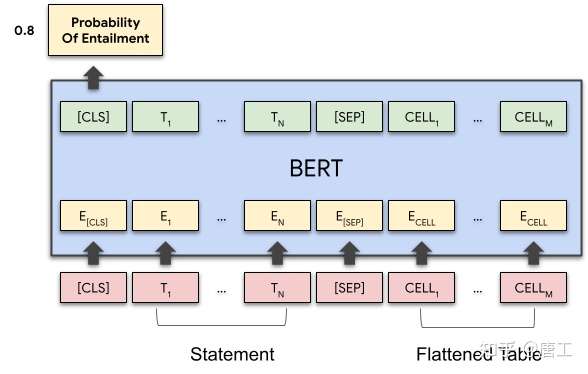
TAPAS 模型是 BERT 双向 Transformer 模型的扩展,将语句和表格的内容编码在一起,通过一个 Transformer 模型传递它们,并通过表格获得一个有可能推导或反驳该语句的概率数值。
KELM 模型:使用语言模型预训练语料库集成知识图谱
KELM (Knowledge-Enhanced Language Model)模型,旨在解决知识图谱(knowledge graphs)这一事实性的结构化数据的结构形式不同,而使得他们很难与现有的语言模型中语料库集成。
KELM 模型,将知识图谱转换为合成的自然语言语句,以增强现有的预训练语料库,使其能够在不改变结构的情况下融入语言模型的预训练。
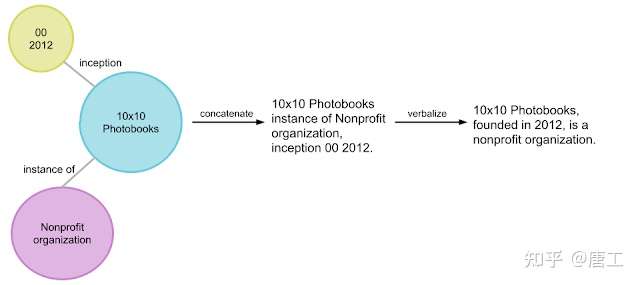
KELM 模型基于检索的语言模型(REALM),并利用合成语料库将自然语言语料库和知识图谱集成到预训练中。

TFT 模型:时间序列预测的可解释性深度学习
TFT (Temporal Fusion Transformer)模型,旨在解决传统的时间序列模型的两类缺点:
- 基于 Transformer 的模型已经使用基于注意力的层来增强相关时间步长(time step)的选择,超越了循环神经网络(RNN) 的归纳偏置(inductive bias)。但是,这些模型没有考虑多时段(multi-horizon)预测中常见的不同输入,或者假定所有的外源输入(exogenous inputs)在未来都是已知的,或者忽略重要的静态协变量(static covariates)。
- 传统的时间序列模型是由许多参数之间复杂的非线性相互作用来控制的,这使得很难解释这些模型是如何预测的。
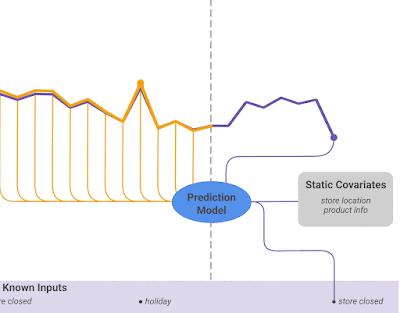
TFT 模型,是一个基于注意力的 DNN 模型的 Transformer 模型,有效地为每个输入类型(即,静态、已知或观测输入)建立特征表示,显式地将模型与一般的多时段预测任务对齐,以获得更高的准确性和可解释性。
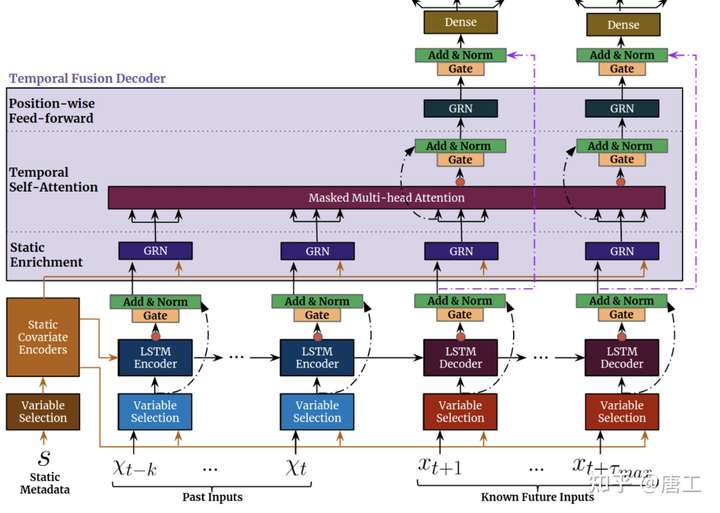
TFT 输入静态元数据、时变的过去输入和时变的先验已知未来输入。变量选择(Variable Selection)用于根据输入明智地选择最显著的特征。添加门控信息作为残差输入,然后进行归一化。门控残差网络 (Gated residual network,GRN) 块通过跳过连接和门控层实现高效的信息流。时间相关处理基于用于本地处理的 LSTM,以及用于集成来自任意时间步长的信息的多头注意力。
参考
Google AI Blog: Google Research: Themes from 2021 and Beyond (googleblog.com)
[2101.04702] Cross-Modal Contrastive Learning for Text-to-Image Generation (arxiv.org)
[2108.10904] SimVLM: Simple Visual Language Model Pretraining with Weak Supervision (arxiv.org)
MURAL: Multimodal, Multitask Retrieval Across Languages – arXiv Vanity (arxiv-vanity.com)
[2111.12993] PolyViT: Co-training Vision Transformers on Images, Videos and Audio (arxiv.org)
Text as Neural Operator: Image Manipulation by Text Instruction (acm.org)
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning | OpenReview
Understanding tables with intermediate pre-training - ACL Anthology
Temporal Fusion Transformers for interpretable multi-horizon time series forecasting - ScienceDirect
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢