

论文:https://arxiv.org/pdf/2203.02636.pdf
代码:
https://github.com/LoraLinH/Boosting-Crowd-Counting-via-Multifaceted-Attention
导读
本文重点关注具有挑战性的人群计数任务。由于密集的人群图像中经常存在大规模的尺度变化,CNN 固定大小的卷积核和Vision Transformer中固定大小的注意力都不能很好地处理这种剧烈的尺度偏移。为了解决这个问题,本文提出了一个多面注意力网络(MAN)来改进局部空间关系编码中的变换器模型。 MAN 将来自 vanilla Transformer 的全局注意力、可学习的局部注意力和实例注意力机制整合到一个模型之中。首先,提出了局部可学习区域注意力(LRA)来动态地为每个特征位置分配注意力。其次,设计了局部注意力正则化,通过最小化不同特征位置的注意力偏差来监督 LRA 的训练。最后,提供了一种 Instance Attention 机制,可以在训练期间动态地关注最重要的实例区域。在 ShanghaiTech、UCF-QNRF、JHU++ 和 NWPU 四个具有挑战性的人群计数数据集上进行的广泛实验验证了所提出的方法。
贡献
人群计数在拥堵估计、视频监控和人群管理中起着至关重要的作用。 特别是在新冠病毒(COVID-19)爆发后,实时人群检测和计数越来越受到管理人员的关注。
近年的人群计数方法利用卷积神经网络 (CNN) 作为主干以生成回归密度图,从而对密度图进行求和来预测人群总数。 然而,由于摄像机的广视角和二维透视投影,人群在图像中的表观经常存在大尺度变化。 具有固定大小卷积核的传统 CNN 难以处理这些变化,其计数性能受到严重限制。 为了缓解这个问题,部分研究设计了多尺度机制,例如多尺度 blobs、金字塔网络和multi-column网络。 这些方法引入了直观的局部结构归纳偏差[43],表明模型的感受野应该与对象的大小适应。
最近,全局自注意力机制的 Transformer 模型的兴起显着提高了各种自然语言处理任务的性能。 尽管如此,直到 ViT引入patch tokenlize作为局部结构归纳偏置,Transformer 模型才能在视觉任务中与 CNN 模型竞争甚至超越 CNN 模型。ViT的发展表明,全局自我注意机制和局部归纳偏差对于视觉任务都很重要。
因此,本文针对现有模型在人群计数领域中面临的两个问题进行了研究:
- 同一张图片中由于远近关系人头大小可能差异很大,但是标签只有点标注,目前 CNN 和 全局 Attention 是没法很好应对这种尺度差异的;
- 有些标签位置不太准确,比如应该在人头正中心却标注的有些偏。
为解决上述问题,本文首先提出了局部可学习区域注意力(LRA)来动态地为每个特征位置分配注意力。其次,设计了局部注意力正则化,通过最小化不同特征位置的注意力偏差来监督 LRA 的训练。最后,提供了一种 Instance Attention 机制,可以在训练期间动态地关注最重要的实例区域。文章一共提出了三个模块,前两个彼此关联,致力于解决第一个尺度差异问题;最后一个则是针对标签噪声,提出了非常简单却可以推广的损失范式。
方法
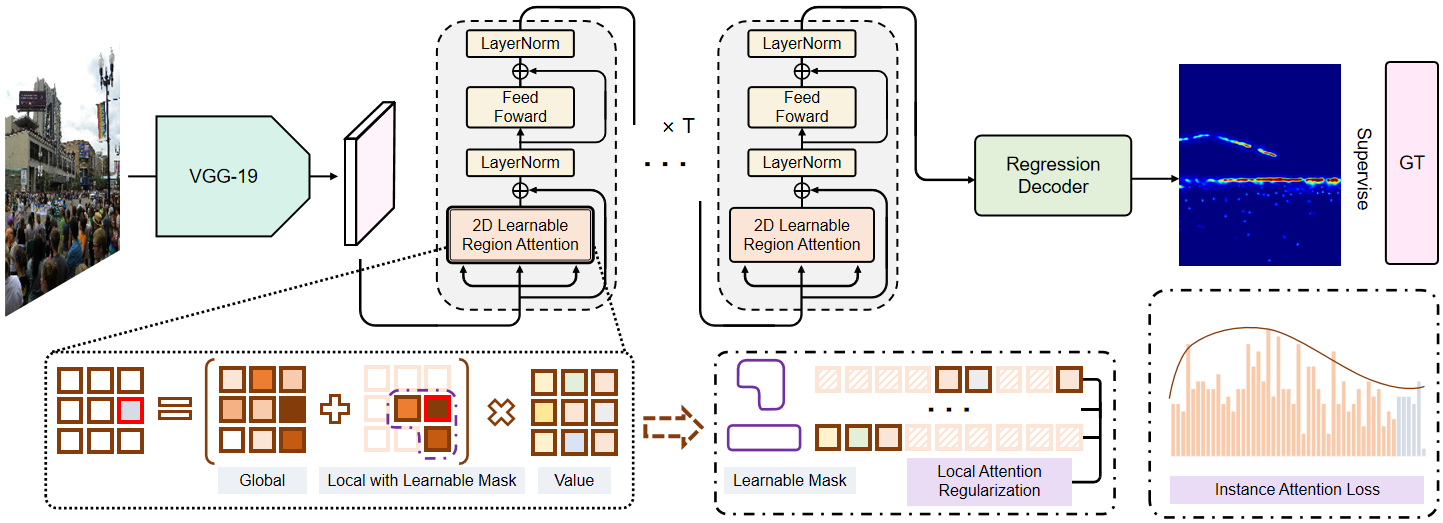
本文提出的Multifaceted Attention Network结构如上图所示。人群图像首先会输入至特征提取backbone,接着,输出特征进入Transformer编码器,该编码器具有Learnable Region Attention机制。最后,一个回归解码器(Local Attention Regularization and Instance Attention Loss)在编码器的基础上生成密度图。
Learnable Region Attention (LRA)
LRA的主要思路是针对每个特征学习一个应该注意的范围,最简单的方式就是整个矩形,毕竟只需要两个点来确定:
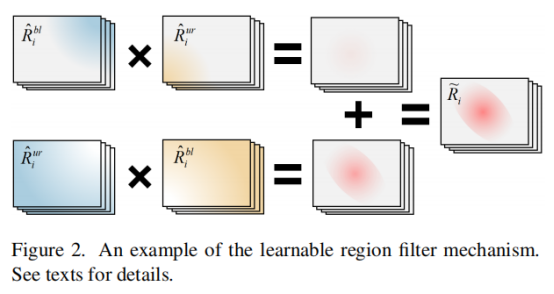
对于图中的任意一点P,其坐标定义为(xp,yp),可以通过坐标点的定义选择相应的矩形区域:
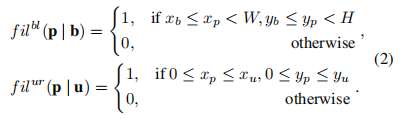

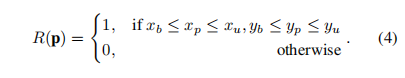
但直接预测两个点是不可微的,其次这样形成的 mask 是严格的 0 / 1,其中比如矩阵中心和矩阵边缘注意力是一样的,灵活性很低。
因此本文利用注意力的角度直接预测一整张图然后把它累积积分起来,具体公式为:
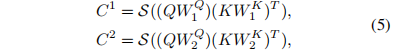
即大小都为 WH*W*H的两张图,第一个维度为特征总数,第二三个维度为每个特征对应的一张预测图。然后为了让它能够形成一个范围,就可以第一张图从左下到右上累积起来,即左下角值为 0,右上角值为总和;那第二张图就从右下到左上累积,这样其实它们两个重复的范围就可以形成一个区域。
但是可能存在一个问题,就比如如果 ur 那张图大部分值都集中在左下角,那么在累积到左下角之前,其他位置是没有值的。如果 bl 也出现了一样的问题,那最后两者相乘可能就没有重复的范围,最后变成了一张都是 0 的图,所以直接再把两个操作反过来:
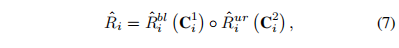
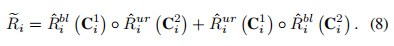
Local Attention Regularization (LAR)
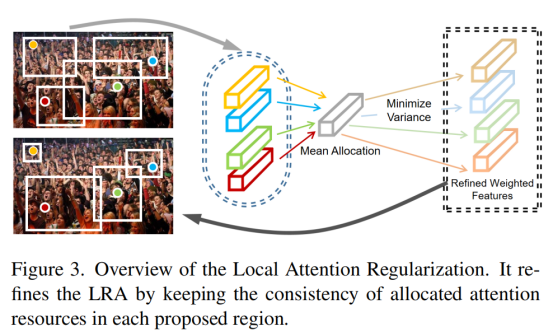
它的目的就是为了监督前一个可学习的局部窗口 LRA,让它满足人头小时注意力窗口就小一点,人头大时,注意力范围自然也要大一点。因此在一个注意力窗口内,人的数量其实应该是差不多的,这样就自然而然地完成了小人头窗口小,大人头窗口大了。模型将从特征层面上来监督这件事:
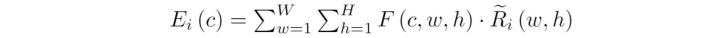
接着直接和平均特征做距离监督:
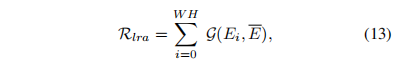
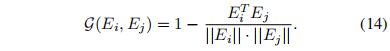
Instance Attention Loss (IAL)
IAL的目的是对每一个惩罚差值加上一个注意力值:
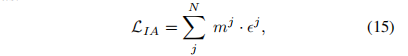
epsilon 就是一个惩罚差值,每个人头的真值即 1 与该位置上像素的后验概率值:
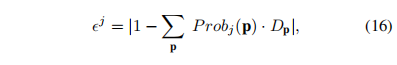
本文只提出了一个最简单的注意力值,就是忽略那些差值过大的,只关注差值合理的前百分之九十,因为本身如果标记错误其产生的误差可能很大:
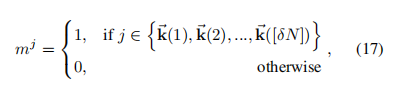
实验
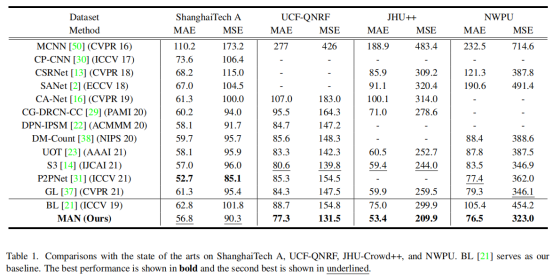
如上表所示,本文在四个数据集上评估MAN模型,并列出了 13 种最近最先进的方法进行比较。结果表明,MAN在所有数据集上都表现出很高的准确度。MAN将次优方法 S3的 MAE 和 MSE 值分别从 80.6 提高到 77.3 和从 139.8 提高到 131.5。
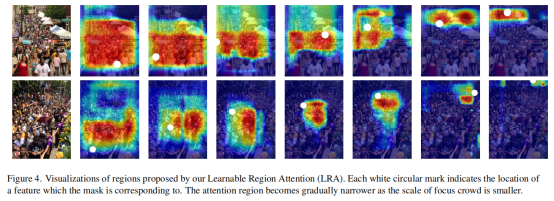
图4显示了可学习区域注意(LRA)的可视化结果。
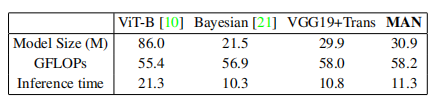
表3报告了在一个384×384输入图像上计算的浮点运算(FLOPs),1024×1024图像的推理时间。可以很容易地观察到,MAN的模型大小和推理时间与VGG19+Trans模型接近,并且比ViT-B模型要小得多。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢