
本文分享一篇 CVPR 2021 论文『Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion』,由伊利诺伊大学厄巴纳-香槟分校、香港科技大学联合快手提出模块化交互式 VOS 算法, MiVOS,所需的交互帧数更低,分割精度与运行效率更高。

作者提出了一种用户交互型视频物体分割框架,通过用户迭代对视频中某些帧进行交互(标注),来提升分割精度。在作者提出的MiVOS解耦框架中,一共分为三个模块,分别为:S2M(用户交互产生分割图)、Propagation(掩码传播)、difference aware fusion(差异感知模块)。
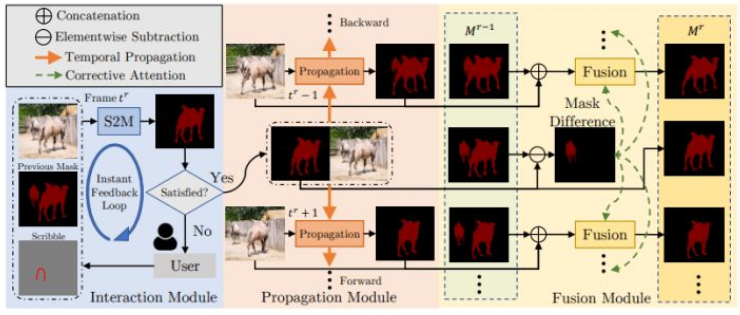
在第r轮交互轮中,用户选择视频中的某一个帧t′,并使用实时运行的Scribble-to-Mask(S2M)模块以交互方式校正掩码,直到满意为止。然后,校正后的掩码将使用传播模块通过视频序列进行双向传播。为了整合前几轮的信息,差异感知融合模块用于融合以前的和当前的掩码。交互前与交互后掩码的差异(这传达了用户的交互意图)通过注意力机制在融合模块中被利用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢