标题:东京大学、谷歌|Large Language Models are Zero-Shot Reasoners(大型语言模型是零样本推理器)
作者:Takeshi Kojima, Shixiang Shane Gu, Yusuke Iwasawa等
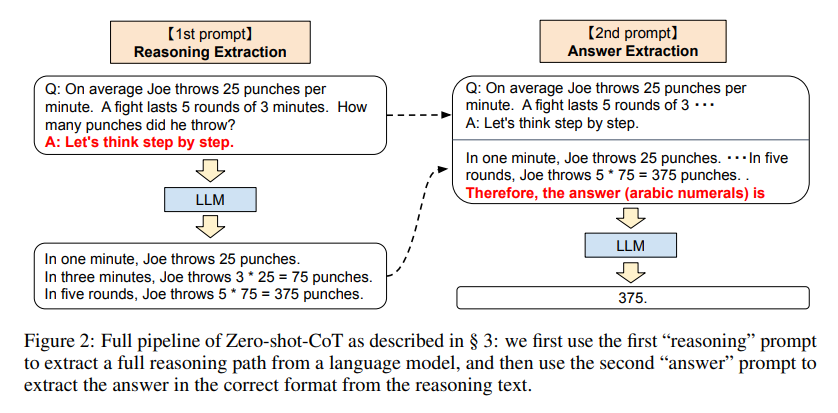
简介:本文研究了大语言模型(LLM)的小样本学习的能力。作者表明LLM是不错的零样本推理者只需在每个答案之前添加“让我们一步一步思考”。实验结果表明,作者的零样本-CoT,使用相同的单个提示模板,在各种基准测试上明显优于零样本LLM性能推理任务:包括算术(MultiArith,GSM8K,AQUA-RAT,SVAMP),符号推理(最后一封信,掷硬币)和其他逻辑推理任务(日期理解,跟踪随机播放的对象),没有任何手工制作的几个样本示例,例如将MultiArith的精度从17.7%提高到78.7%和GSM8K从10.4%到40.7%,利用现成的175B参数模型。这个单一提示在非常多样化的推理任务中的多功能性,暗示LLM的基本零样本能力尚未得到开发和充分研究,这表明高水平多任务的广泛认知能力可以通过简单方法完成。作者希望这次工作不仅能成为具有挑战性的推理基准的最小最强零样本基线,而且还能仔细探索和分析零样本知识的重要性。
论文下载:https://arxiv.org/pdf/2205.11916v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢