
全世界有7000多门语言,但自然语言处理(NLP)却主要研究英语这门语言。来自Deep Mind的科研人员Sebastian Ruder认为,当下NLP领域集中于开发能够有效处理英语的方法,却忽略了钻研其他语言的重要性。事实上,研究英语以外的语言不仅具有重大的社会意义,还有助于构建多语言特征模型,以避免过度拟合和应对机器学习的潜在挑战。
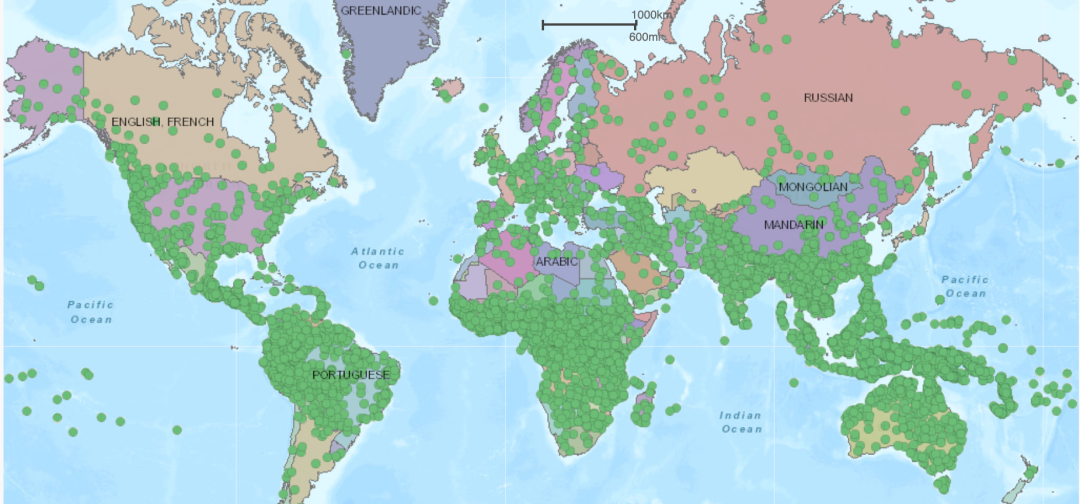 (在上面的地图中,一个绿色圆圈便代表一种本土语言。世界上大多数语言的使用集中分布在亚洲、非洲、太平洋地区和美洲地区。)
(在上面的地图中,一个绿色圆圈便代表一种本土语言。世界上大多数语言的使用集中分布在亚洲、非洲、太平洋地区和美洲地区。)
在过去的几年里,NLP的许多任务取得了振奋人心的进步,但大多数成果只是局限于英语和其他少数几门使用较广泛、数据资源丰富的语言,如中文、日语、法语等。作者Sebastian Ruder回顾2019年ACL网站上关于无监督跨语言表示学习(Unsupervised Cross-lingual Representation Learning)的发文,然后基于线上所能获取的无标注数据和标注数据,总结出一个语言数据资源等级体系。这个体系与2020年由来自微软研究院的Pratik Joshi等人共同发表在ACL上的一篇论文“The State and Fate of Linguistic Diversity and Inclusion in the NLP World”里所提到的分类法相似,如下图所示:
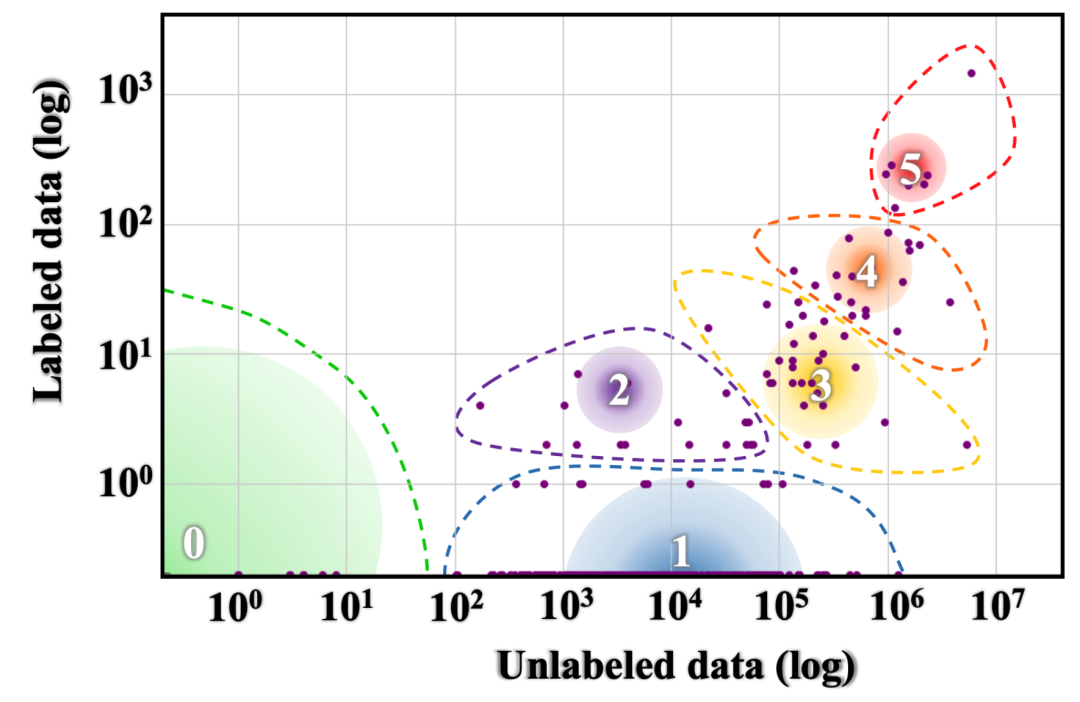 (这是Joshi等人归纳的语言资源分布图。圆圈的大小和颜色分别表示一个语系下的语言数量和使用者数量。根据VIBGYOR光谱的排列顺序:紫色(Violet)–靛蓝(Indigo)–蓝色(Blue)–绿色(Green)–黄色(Yellow)–橙色(Orange)–红色(Red),颜色从左到右(从紫色到红色)表示语言使用者数量递增。)
(这是Joshi等人归纳的语言资源分布图。圆圈的大小和颜色分别表示一个语系下的语言数量和使用者数量。根据VIBGYOR光谱的排列顺序:紫色(Violet)–靛蓝(Indigo)–蓝色(Blue)–绿色(Green)–黄色(Yellow)–橙色(Orange)–红色(Red),颜色从左到右(从紫色到红色)表示语言使用者数量递增。)
从上图中,我们可以看到,当下NLP文献对分布在最右边的、拥有大量标注数据和未标注数据的第5类语言(红色)和第4类语言(橙色)有充分研究。相比之下,NLP对其他组别的语言研究十分有限。在本文中,作者将从社会、语言、机器学习、文化规范以及认知等视角论证NLP为何需要钻研英语以外的其他语言。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢