


论文:https://arxiv.org/abs/2203.09770
代码:https://github.com/thunlp/OpenPrompt
导读
针对预训练语言模型(PLM)的提示微调(prompt-based tuning)在少次学习中十分有效。通常,提示微调会将输入文本包装成填空问题。为了做出预测,这种方法通过一个表达器(verbalizer)将输出的单词映射到标签上。该表达器可以是人工设计的,也可以是自动构建的。然而,人工表达器严重依赖于特定领域的先验知识,而自动寻找合适的标签词仍然是一项挑战,本文提出了直接从训练数据中构建的原型表达器ProtoVerb。具体而言,ProtoVerb通过对比学习将学到的原型(prototype)向量作为表达器。通过这种方式,原型归纳了训练实例,并且能够包含丰富的类级别语义。我们在主题分类和实体分类任务上进行了实验,实验结果表明,ProtoVerb的性能明显优于现有的自动生成的表达器,特别是在训练数据极其匮乏的场景下。更令人惊讶的是,即使是在未微调的预训练语言模型上,ProtoVerb也能够提升提示微调的性能,这表明ProtoVerb也是一种优雅的非微调预训练模型利用方式。
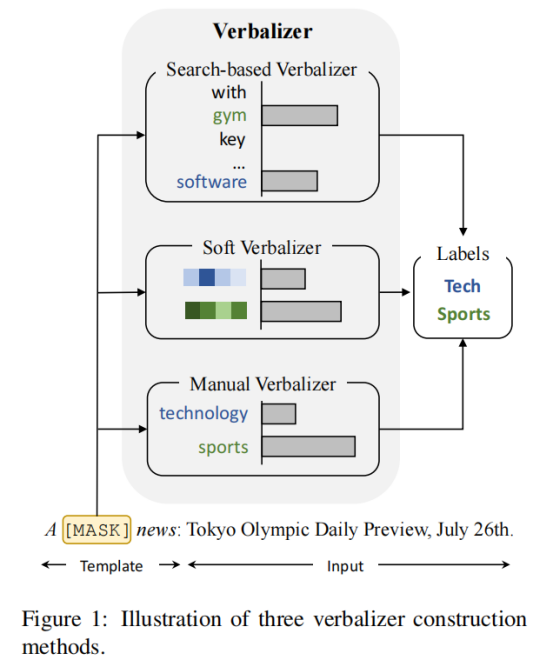
贡献
大规模预训练语言模型 (PLM) 已被证明是解决各种 NLP 任务的有效手段。 为了进一步使这些 PLM 适应分类等下游任务,传统方法通过额外的分类器微调语言模型。 然而,当特定下游任务的可用数据有限时,PLM将会受限于预训练任务与下游任务之间的差异,难以快速地将PLM迁移至下游任务中。
最近,基于提示的调优被证明可以缓解预训练阶段和下游任务阶段之间的差距,成为了小样本学习的有效方法。 在基于提示的调优中,输入文本使用特定于任务的模板进行包装,以将原始任务重新形式化为完形填空式任务。 例如,在主题分类任务中,我们可以使用模板“<text> This topic is about [MASK]”,其中<text>是输入句子的占位符,要求 PLM 推断要填写的单词 [MASK],然后通过语言器将单词进一步映射到相应的标签(例如,标签“体育”的“体育”)。 作为模型输出和最终预测之间的桥梁,Verbalizers 在基于提示的调优中非常重要。因此,如何为基于提示的调优(尤其是多类分类)构建有效的语言化器是基于提示的调优中的一个关键问题。
之前研究中verbalizer设计方法主要包括manual verbalizer,search-based verbalizer以及soft verbalizer等。manual verbalizer的设计取决于domain-specific prior knowledge以及human efforts;而search-based verbalizer以及soft verbalizer的方法在low-data regime的情形下很难在large vocabulary或者embedding space中寻找或获得比较好的verbalizer。与上述研究不同,作者尝试通过估计出分类问题的每一类别的prototype vectors来作为verbalizer. 并使用带有InfoNCE estimator的对比学习来训练出prototype vectors.
方法
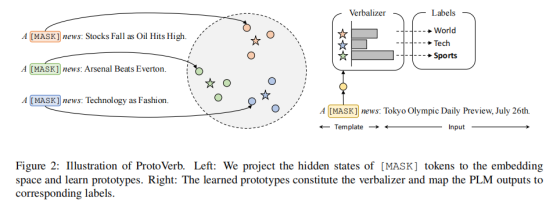
对于给定的训练文本text x , 在被template wrap以后,将[MASK] token的最后一层特征h[mask]作为initial representation,使用编码器来获得X的instance表示。
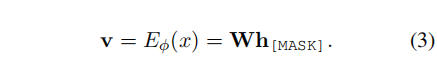
为了衡量instances之间的similarity,采用余弦相似度进行计算:
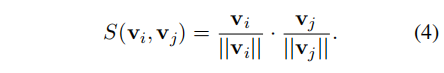
将C={c1,c2,...cn}表示为prototype vectors的集合。
(1) 对于instance-instance pairs,intra-class pairs应该比inter-class pairs在similarity scores上得分更高。
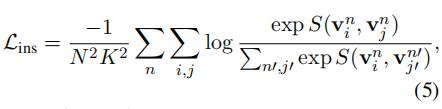
(2) 对于instance-prototype pairs,prototype cn和class n的instances的similarity scores应该比cn和其他类别的instances的相似度高。
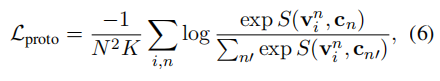
最终的training objective是:
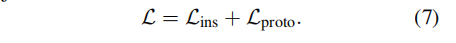
在inference阶段,计算query与prototypes vector之间的similarity scores,对类别k,有:
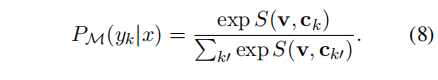
根据arg max function来预测:
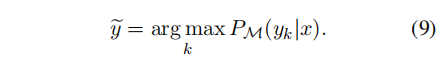
实验
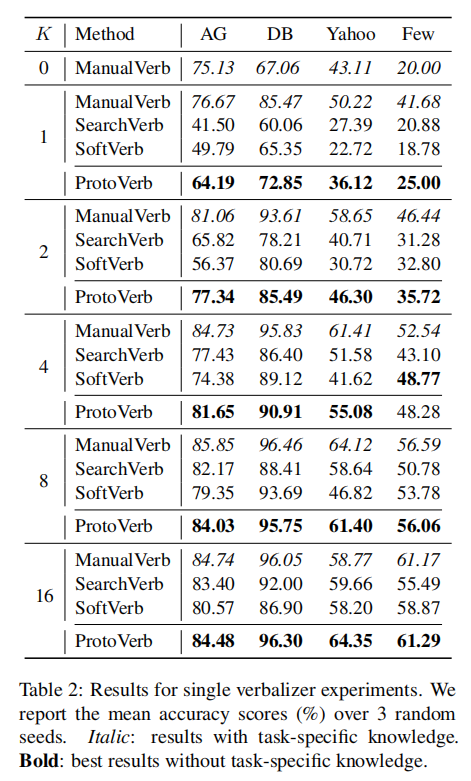
2.1 Single Verbalizer Results
ProtoVerb在小样本的情况下,尤其是在每类只有1 or 2 instances 的情况下表现远远甚于SearchVerb和SoftVerb. 当训练样本sufficient时,ProtoVerb能够达到超越ManualVerb的表现。
2.2 Multiple Verbalizer Results
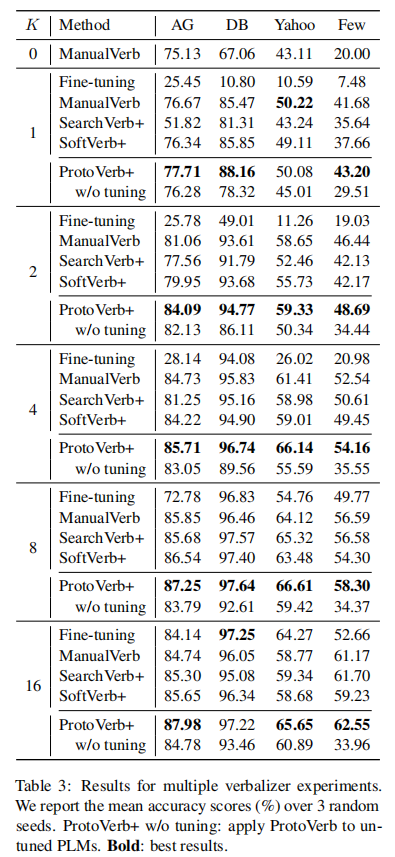
- 在小样本的情况下,prompt-based tuning远远超过fine-tuning方法。当有足够训练数据时,fine-tuning模型也能够产生相当的结果。
- ProtoVerb + ManualVerb方法结合时,能够产生更好的结果。
- ProtoVerb+在untuned PLMs上仍然非常有效,证明了这种no-tuning method的有效性。
3. Analysis
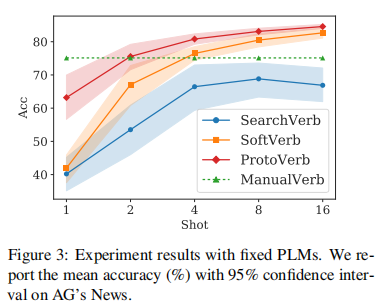
3.1 Fixed Model Experiments
定量分析当PLMs固定时verbalizers的影响
3.2 Ablation Study
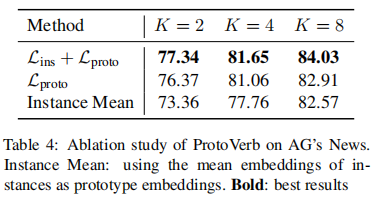
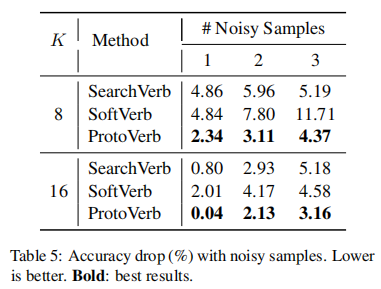
3.3 Robustness on Noisy Samples
3.4 Prototype Discretization
作者收集了每一类中最similar的词语,可以这样理解,prompt机制使得PLMs能够选择最conclusive的信息,并且在[MASK]位填上。可以看到随着training instances的增加,更"conceptual"的词语会出现表格中。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢