
在CVPR 2022上,商汤研究团队提出了一种通过特征聚类生成动态视觉令牌(vision token)的 Transformer 网络——TCFormer。TCFormer 能够根据图像的语义信息,调整视觉令牌的形状、大小和位置,从而更好地提取图像的细节信息。此外,本文还提出了一种新的多层特征聚合模块,能够更好地保留动态令牌中的细节信息。TCFormer 在基于图像的人体全身关键点估计、人脸关键点估计和人体三维网格重建任务上都获得了最先进的效果,并在人体细节的重建精度上取得了明显的提升。

论文链接:
https://arxiv.org/abs/2204.08680
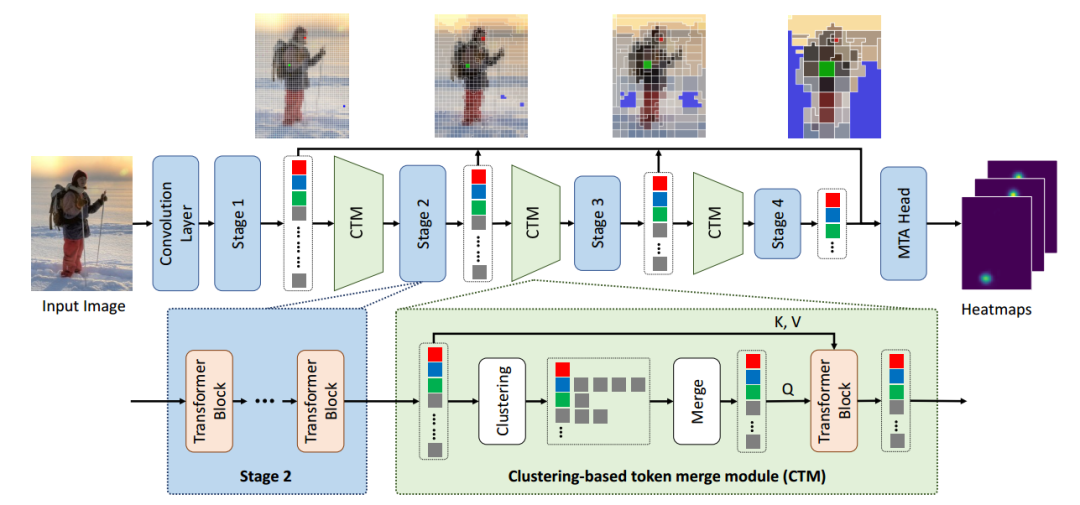
下图展示了 TCFormer 的整体框架。TCFormer 采用了多阶段(stage)的网络框架,共由4个不同的阶段组成,每个阶段又由多个串联的 transformer 模块组成。将图片输入 TCFormer 后,我们首先通过卷积层提取图像特征图,并将特征图中的每一个像素当作一个视觉令牌,从而得到初始的视觉令牌。在相邻的两个阶段之间,我们通过令牌融合的方式减少令牌数目,并增加令牌特征的通道数。最后,我们通过一个多阶段令牌特征聚合模块(MTA)融合各个阶段的令牌特征。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢