

论文链接:https://arxiv.org/pdf/2204.12484v2.pdf
开源地址:https://github.com/ViTAE-Transformer/ViTPose
导读
ViT制霸CV领域已是不争的事实,基于ViT的姿态估计模型也已经出了不少,如PRTR、TokenPose、HRFormer等,它们有的使用了级联策略来逐层refine关键点,有的只使用了Transformer编码器用于对CNN特征进行学习,或者通过模仿HRNet结构,将Transformer作为一个学习能力更强的模块替换使用。它们要么需要CNN来提特征,要么对网络结构进行了复杂的设计,但是通过之前很多工作(ViTDet、MAE等)可以发现,纯ViT实际上潜力是非常巨大的,只不过需要庞大的计算量和数据量支撑。所以很自然地,秉承着Money is all you need的原则,本文探索了纯ViT结构在姿态估计任务上的表现,并且再一次证明了只要算力足够,纯ViT还是能够大力出奇迹。
贡献
人体姿态估计是计算机视觉领域的基本研究问题之一,具有很广泛的实际应用,例如医疗健康领域的行为分析、元宇宙领域的AIGC内容生成等。但是,由于人体姿态丰富,人物衣着表观变化多样,光照和遮挡等因素,人体姿态估计任务非常具有挑战性。之前的深度学习方法主要研究了新的骨干网络设计、多尺度特征融合、更强的解码器结构和损失函数设计等。
近期,基于vision transformer的人体姿态估计算法开始在学术界流行起来。通过设计精巧的递归逐次解码结构,或者是采用多尺度并行的高分辨率特征融合,它们在人体姿态估计任务上取得了很好的结果。然而,简单的vision transformer结构是否就能够解决人体姿态估计任务尚缺乏研究。在本项研究中,作者从模型尺寸,输入分辨率,特征分辨率,预训练等多个方面探讨了简单的vision transformer在人体姿态估计任务上的表现。
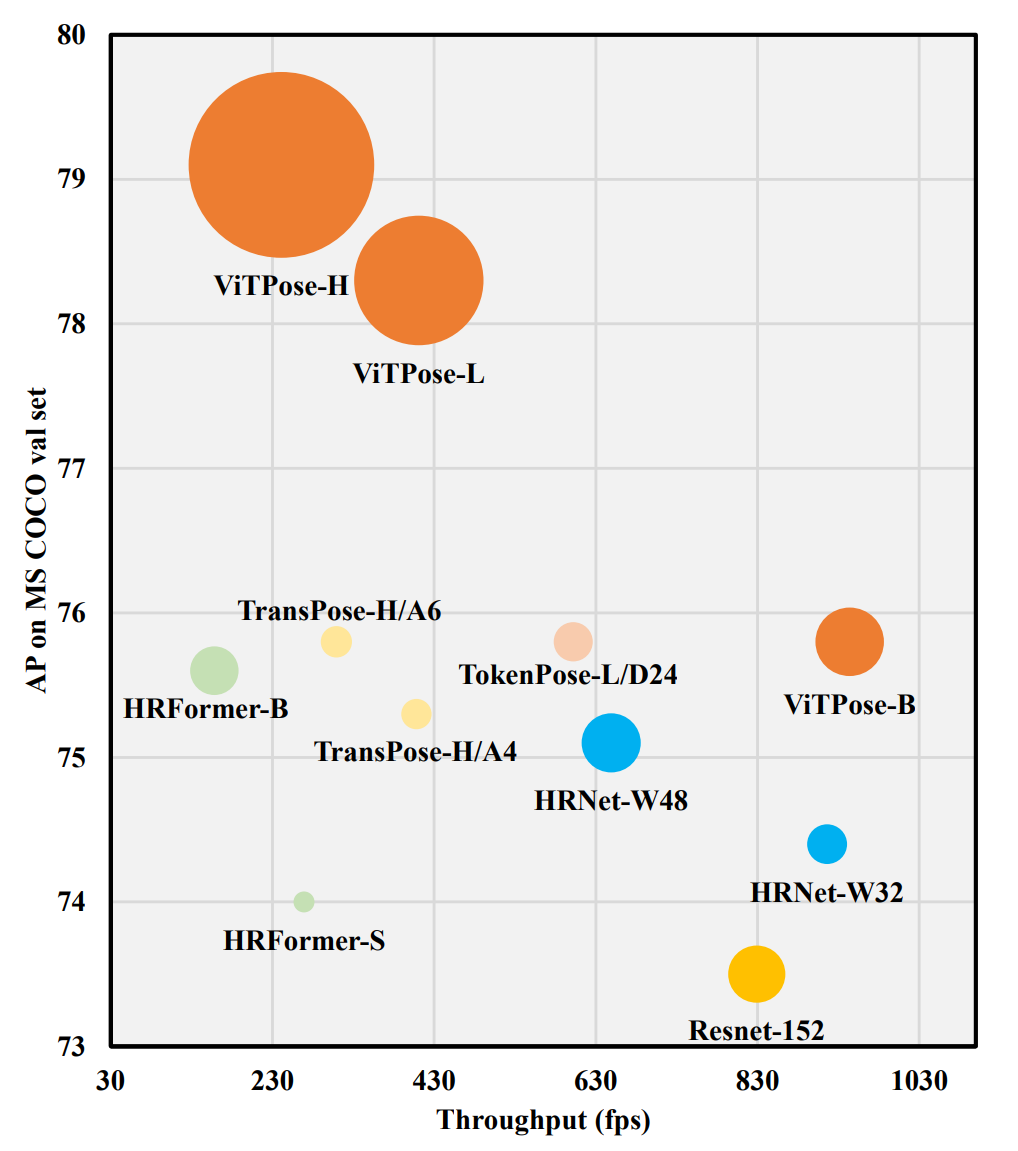
出于尽可能不使用精巧的设计并最大化探索vision transformer本身作用的考虑,作者直接将人体图像输入到vision transformer进行特征提取,并用简单的反卷积层对所得到的特征进行解码,最后对解码特征进行双线性上采样得到人体关键点热图。基于ViT-B骨干网络,这样一个简单的结构在MS COCO验证集上即可达到75.8 AP的检测精度,其性能与目前基于vision transformer的最强的人体姿态估计算法相当。
本文的主要贡献可以总结如下:
- 实验了纯ViT用于人体姿态估计,在COCO数据集上取得了SOTA表现。
- 验证了纯ViT所具有的诸多良好特性:结构简单、模型规模容易扩展、训练灵活、知识可迁移。
- 在多个benchmark上进行了实验和分析。
方法
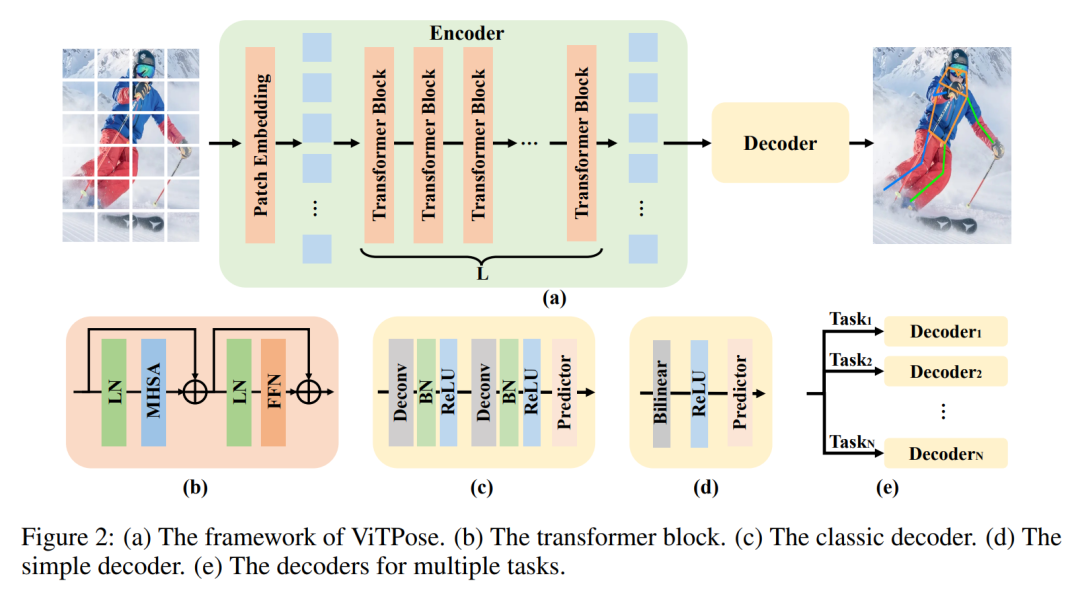
本文的目标是为姿势估计任务提供一个简单而有效的Vision Transformer基线,并探索普通和非分层Vision Transformer的潜力。其核心出发点其实与ViTDet是相似的,简单来说都是相信最原始的ViT有很高的学习能力上限,不需要加那么多花里胡哨的设计、做那么多复杂的改进,也能学出足够高质量的特征。这里的“复杂设计”包括了:用CNN作为Backbone提取特征、效仿CNN的层次化设计改进ViT、效仿HRNet在结构上维持高分辨率特征等等。
与已有研究ViTDet类似,作者认为直接用ViT的最后一层特征做简单的上下采样,就能作为不同尺度上的特征使用。而不必像传统CNN那样从不同的stage抽特征,也不必像FPN那样做top-down和bottom-up的不同尺度特征融合。
姿态估计作为关键点检测任务的一种,在设计思想上与目标检测任务其实很多地方都是大同小异的,所以很自然地也可以沿用上述观点。
因此,本文使用的网络结构也就是最简单粗暴的方案,直接用纯ViT作为编码器进行特征学习,对学到的特征用简单的解码器解码获得关键点预测结果。
与ViT类似,ViTPose同样将图像Token作为输入,并使用多头注意力机制MHSA、前向传播网络FFN进行特征编码:
![]()
而在解码阶段,作者提出分别采用两种不同大小的卷积层生成姿态检测结果:
![]()
![]()
从上述讨论中可以发现,ViTPose的模型结构非常简单,尽管如此,作者发现这些设置仍带来了simplicity、scalability、flexibility、transferability四种特性。
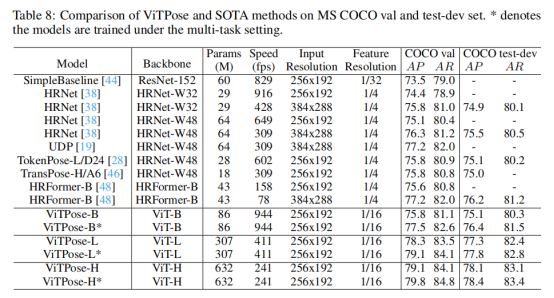
出于尽可能不使用精巧的设计并最大化探索vision transformer本身作用的考虑,作者直接将人体图像输入到vision transformer进行特征提取,并用简单的反卷积层对所得到的特征进行解码,最后对解码特征进行双线性上采样得到人体关键点热图。基于ViT-B骨干网络,这样一个简单的结构在MS COCO验证集上即可达到75.8 AP的检测精度,其性能与目前基于vision transformer的最强的人体姿态估计算法相当。当使用更大的分辨率和更大的模型尺寸,如下表所示,本文的ViTPose模型可以取得更好的人体姿态估计效果。这体现了ViTPose良好的扩展性和灵活性。

在之前的工作中,ImageNet预训练对于vision transformer在下游任务上的泛化性能具有重要作用。但是,由于人体姿态估计数据集本身包含了大量的人体实例图像,作者怀疑是否有必要继续使用大型ImageNet数据集进行vision transformer的预训练。为此,作者分别测试了采用ImageNet数据(100万张分类图像)和仅仅使用人体姿态估计数据(50万张人体图像)进行MAE自监督预训练对人体姿态估计任务的性能影响。作者发现对于人体姿态估计任务,采用人体姿态估计数据进行预训练即可得到与采用更大规模的ImageNet数据集进行预训练相当的性能。

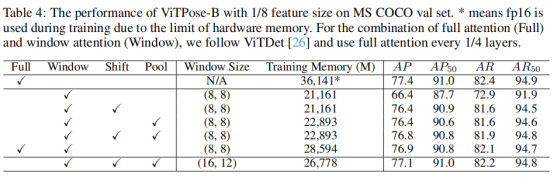
此外,之前的研究表明使用更大的特征分辨率,如1/4尺寸的特征,可以得到更为精细的人体关键点热图和更好的人体姿态估计结果。在这里,作者也探索了特征分辨率对ViTPose性能的影响。需要注意的是,与卷积神经网络不同,采用更大的特征分辨率会对vision transformer带来更多的显存占用和计算开销。因此,作者把vision transformer所有层的全局注意力运算改为窗口注意力运算,从而降低显存消耗和计算量。结果如表4所示,基于全窗口注意力的ViT-B作为骨干网络的ViTPose模型,由于缺乏窗口间的信息交互,使用更大分辨率特征(1/8)的性能(72.0AP),反而不如原始的ViTPose模型使用低分辨率特征(1/16)的性能(75.8AP)。为了解决这个问题,作者采用了探索研究院之前提出的ViTAE transformer作为骨干网络。ViTAE模型采用了并行的卷积分支和注意力分支结构,其卷积分支可以促进窗口间的信息交互。采用了ViTAE-B作为骨干网络,ViTPose在使用更大分辨率特征时取得了相比ViT-B更好的结果,也优于使用低分辨率特征的模型结果。
实验
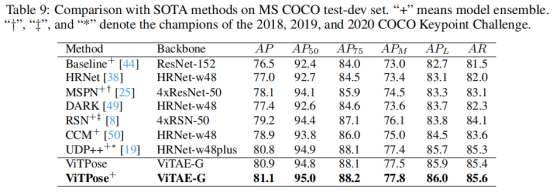
作者在COCO的测试集上对作者所提出的ViTPose方法和之前的代表性方法进行了比较,结果如表5所示。在不采用模型集成的情况下,使用ViTAE-G作为骨干网络的ViTPose已经取得了世界第一的结果,超过了采用了17个模型进行集成并使用了更强的目标检测器进行人体的检测的2020年冠军方案。采用4个ViTPose模型进行集成,作者的方法可以取得81.1AP的最佳性能。该结果充分说明了vision transformer模型在人体姿态估计方面的潜力和适应性。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢