
本文介绍阿里妈妈外投广告 UD 算法团队在预估校准方向的实践与探索,该项工作论文已发表 SIGIR 2022。

论文: Posterior Probability Matters: Doubly-Adaptive Calibration for Neural Predictions in Online Advertising
下载: https://arxiv.org/abs/2205.07295
1. 背景
对用户行为(如点击/转化/停留时长/二跳/收藏/加购等)概率进行精准预估是在线广告平台以及搜推系统的核心能力,基于大规模离散特征的 DNN 模型已成为精排模块的事实标准。关于精排模型的迭代,大多时候是从优化排序关系的角度出发,如果单纯从 AUC 提升来说,预估值是否有严格的概率意义并不十分重要;而在广告场景下对预估值的准确性有着额外的要求:例如在 oCPX 模式下,模型对每条流量给出的点击率/转化率预估值会直接作用于出价,因此我们希望预估值能够反映用户行为事件发生的实际概率来实现对流量价值的精准判断;对广告平台而言,模型预估值会影响扣费与结算,因此预估值应避免出现过高估计或过低估计的情况。阿里妈妈外投广告的效果类业务以 oCPX 模式为主,预估值的准确性提升一直是模型侧与机制侧在迭代中追求的目标。由于单个样本的行为概率不可知(仅能观测到行为是否发生),对于预估值的准确性的评估通常是按某一特征来聚合相应的样本后,比较模型在样本集合上的预估值相较于样本集上统计出的后验概率的偏离程度,例如若某一个 ad_id 的所有样本的平均点击率为 0.02 则我们希望在该 ad_id 上的模型预估值均值也接近 0.02。因此,对于预估值的准确性的要求一般是在特征粒度上的。同样由于单个样本的真实概率未知,预估模型的训练只能以二值分类为学习目标而做不到以连续值回归为目标,这就导致模型预估值的准确性往往不尽人意。此外,模型学习的收敛性情况、额外的样本采样、引入了额外 loss 等操作均会对预估值的准确性产生影响。业界广泛使用的提升预估值准确性的方式是校准(calibration) :校准模块通常处在精排模型之后,基于后验信息将精排模型给出的预估值进行一次映射,使其更加逼近后验概率,预估值经过这样的后处理之后再去参与排序、出价等。预估模型通常是基于大规模离散特征的 DNN,相比之下,校准模块以轻量化的转换函数为主。在看似“矛盾”的设置背后,我们开始思考能否通过 DNN 的强大拟合能力来助力预估值的准确性提升,并探索预估和校准是否有合二为一的可能。沿着预估&校准一体化这个思路我们展开了初步尝试,提出后验引导的特征自适应校准模型 AdaCalib。AdaCalib 通过引入后验统计量,基于 DNN 来学习校准函数族,指定的待校准特征域下的每个特征取值会对应一个特定的校准函数。同时,针对不同特征取值的频数信息存在差异的现象,通过自适应分桶机制来保证每个特征取值的校准函数所依赖的后验信息的可靠性。在线 serving 时,AdaCalib 被合入预估模型的 ckpt 中、推送至 RTP,相当于校准直接在精排模块生效,而不再维护单独的校准模块。在 RTA 效果外投场景上的在线实验表明 AdaCalib 在 CVR 等指标上取得了明显效果。
2. Preliminaries
2.1 相关工作
业界常用的校准方法大致上可分为三类:(1)Binning-based 方法:以保序回归 (Isotonic Regression, IsoReg) [1] 为代表,将样本按模型预估值升序排列后分桶并计算桶内的后验概率(若连续的两个桶的后验概率不满足升序则进行合并桶,直到各桶的后验值满足升序),将桶内后验值作为桶内全部样本的校准后预估值。此类方法的优势在于校准不会影响预估模型对样本的排序,但通常是非参的、表达能力受限,并且不能给出样本粒度的校准值。(2)Scaling-based 方法:以 Platt Scaling [2]、Gamma Calibration [3] 等为代表,通常是学习参数化的函数将 logit 进行映射来完成校准(该类方法被用于对 SVM 等输出无明显概率意义的模型进行校准,因此不是直接对预估值做校准),通过假设概率服从某类特定分布,来给出校准函数中待学习的参数,不同的参数化形式对应于对分布的不同假设。这类方法的表达能力强,但各种分布假设都可能有其适用性的问题。(3)Hybrid 方法:以 Smoothed IsoReg (SIR) [4] 和 Neural Calibration (NeuCalib) [5] 为代表,该类方法结合了 binning 和 scaling 两类方法的优势。SIR 在 IsoReg 基础上通过线性插值 scaling 来得到每个样本的校准后预估值,因此校准函数为分段线性的形式。NeuCalib 提出了特征粒度校准 (field-aware calibration) 的概念,即认为给定特征域 (field) 下的不同特征取值 (field value) 应该有不同的校准函数,因为不加区分地用全局后验作为校准依据时会出现一些样本被抬高而另一些样本被拉低的情况。方法层面上,NeuCalib 采用将 logit 分桶后学习一个全局的分段线性函数作为校准函数,并在映射后的 logit 上添加了一路辅助网络来补充特征信息,最终经过 scaling 来给出校准值。以上方法仅有 NeuCalib 涉足了特征粒度校准,然而其校准函数的学习过程依然与特征无关。
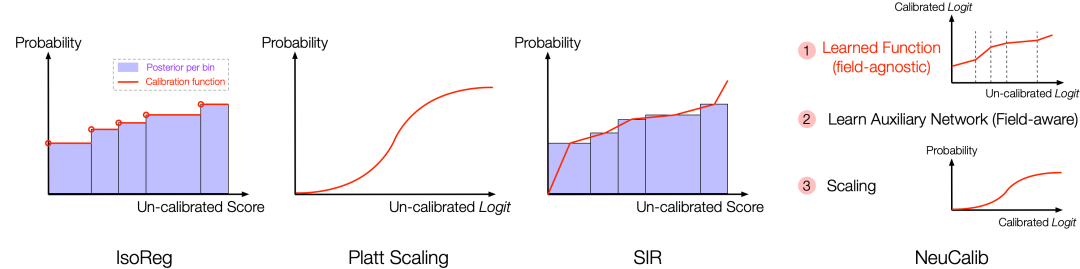
图1:各类方法的校准函数示意
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢