

论文标题:Can CNNs Be More Robust Than Transformers?
论文链接:https://arxiv.org/abs/2206.03452
代码链接:https://github.com/UCSC-VLAA/RobustCNN
作者单位:加州大学 & 约翰斯·霍普金斯大学
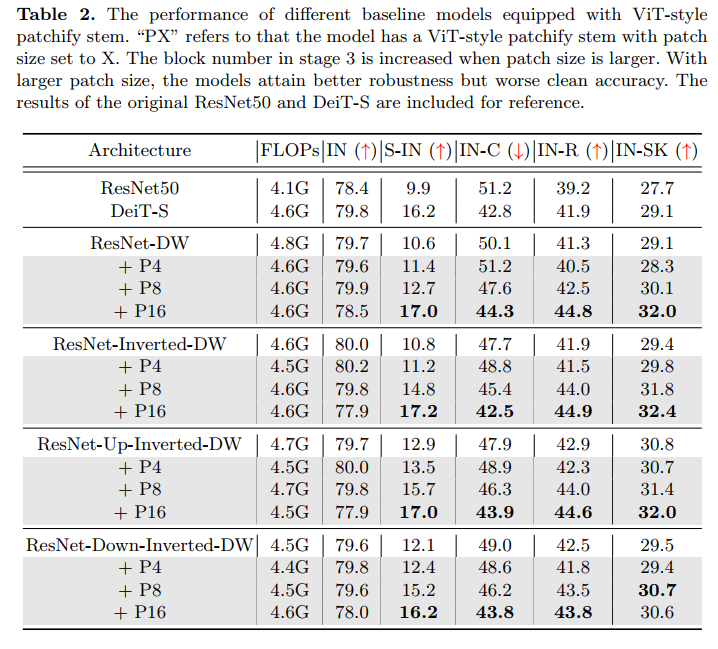
Vision Transformers 最近的成功正在动摇卷积神经网络 (CNN) 在图像识别领域长达十年的主导地位。具体来说,就分布外样本的鲁棒性而言,最近的研究发现,无论训练设置如何,Transformer 本质上都比 CNN 更鲁棒。此外,人们认为 Transformer 的这种优越性在很大程度上应归功于其类似自我注意的架构本身。在本文中,我们通过仔细检查Transformers的设计来质疑这种信念。我们的研究结果导致了三种高效的架构设计来提高鲁棒性,但足够简单,可以在几行代码中实现,即 a) 修补输入图像,b) 扩大内核大小,以及 c) 减少激活层和规范化层。将这些组件组合在一起,我们能够构建纯 CNN 架构,而无需任何类似注意力的操作,这些操作与 Transformers 一样健壮,甚至更健壮。我们希望这项工作可以帮助社区更好地理解鲁棒神经架构的设计。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢