
随着互联网产生的文本数据越来越多,文本信息过载问题日益严重,对各类文本进行一个“降维”处理显得非常必要,而文本摘要就是其中一个重要的手段。
本文首先介绍了经典的文本摘要方法,随后分析了对话摘要的模型,并分享了美团在真实对话摘要场景中面临的挑战。同时基于实际的场景,本文提出了阅读理解的距离监督Span-Level对话摘要方案(已发表在SIGIR 2021),该方法比强基准方法在ROUGE-L指标和BLEU指标上提升了3%左右。
1. 对话摘要技术背景
文本摘要[65-74]旨在将文本或文本集合转换为包含关键信息的简短摘要,是缓解文本信息过载的一个重要手段。文本摘要按照输入类型,可分为单文档摘要和多文档摘要。单文档摘要从给定的一个文档中生成摘要,多文档摘要从给定的一组主题相关的文档中生成摘要。按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要信息全部来源于原文。生成式摘要根据原文,允许生成新的词语、短语来组成摘要。此外,按照有无监督数据,文本摘要可以分为有监督摘要和无监督摘要。根据输入数据领域,文本摘要又可以分为新闻摘要、专利摘要、论文摘要、对话摘要等等。
自动文本摘要可以看作是一个信息压缩的过程,我们将输入的一篇或多篇文档自动压缩为一篇简短的摘要,该过程不可避免地存在信息损失,但要求保留尽可能多的重要信息。自动文摘系统通常涉及对输入文档的理解、要点的筛选以及文摘合成这三个主要步骤。其中,文档理解可浅可深,大多数自动文摘系统只需要进行比较浅层的文档理解,例如段落划分、句子切分、词法分析等,也有文摘系统需要依赖句法解析、语义角色标注、指代消解,甚至深层语义分析等技术。
对话摘要是文本摘要的一个特例,其核心面向的是对话类数据。对话类数据有着不同的形式,例如:会议、闲聊、邮件、辩论、客服等等。不同形式的对话摘要在自己的特定领域有着不同的应用场景,但是它们的核心与摘要任务的核心是一致的,都是为了捕捉对话中的关键信息,帮助快速理解对话的核心内容。与文本摘要不同的是,对话摘要的关键信息常常散落在不同之处,对话中的说话者、话题不停地转换。此外,当前也缺少对话摘要的数据集,这些都增大了对话摘要的难度[64]。
基于实际的场景,本文提出了阅读理解的距离监督Span-Level对话摘要方案《Distant Supervision based Machine Reading Comprehension for Extractive Summarization in Customer Service》(已发表在SIGIR 2021),该方法比强基准方法在ROUGE-L指标和BLEU指标上提升了3%左右。
2. 文本摘要与对话摘要经典模型介绍
文本摘要从生成方式上可分为抽取式摘要和生成式摘要两种模式。抽取式摘要通常使用算法从源文档中提取现成的关键词、句子作为摘要句。在通顺度上,一般优于生成式摘要。但是,抽取式摘要会引入过多的冗余信息,无法体现摘要本身的特点。生成式摘要则是基于NLG(Natural Language Generation)技术,根据源文档内容,由算法模型生成自然语言描述,而非直接提取原文的句子。
目前,生成式摘要很多工作都是基于深度学习中的Seq2Seq模型[44]。最近在以BERT[34]为代表的大量预训练模型出世后,也有很多工作集中在如何利用预训练模型来做NLG任务。下面分别介绍上述两种模式下的经典模型。
2.1 抽取式摘要模型
抽取式摘要从原文中选取关键词、关键句组成摘要。这种方法天然在语法、句法上错误率低,保证了一定的效果。传统的抽取式摘要方法使用图方法、聚类等方式完成无监督摘要。目前流行的基于神经网络的抽取式摘要,往往将问题建模为序列标注和句子排序两类任务。下面首先介绍传统的抽取式摘要方法,接着简述基于神经网络的抽取式摘要方法。
传统抽取式摘要方法
Lead-3
一般来说,文档常常会在标题和文档开始就表明主题,因此最简单的方法就是抽取文档中的前几句作为摘要。常用的方法为Lead-3[63],即抽取文档的前三句作为文档的摘要。Lead-3方法虽然简单直接,但却是非常有效的方法。
TextRank
TextRank[58] 算法仿照PageRank,将句子作为节点,使用句子间相似度,构造无向有权边。使用边上的权值迭代更新节点值,最后选取N个得分最高的节点,作为摘要。
聚类
基于聚类的方法,将文档中的句子视为一个点,按照聚类的方式完成摘要。例如Padmakumar和Saran [11]将文档中的句子使用Skip Thought Vectors和Paragram Embeddings两种方式进行编码,得到句子级别的向量表示。然后再使用K均值聚类[59]和Mean-Shift聚类[60]进行句子聚类,得到N个类别。最后从每个类别中,选择距离质心最近的句子,得到N个句子,作为最终的摘要。
基于神经网络的抽取式摘要方法
近年来神经网络风靡之后,基于神经网络的抽取式摘要方法比传统的抽取式摘要方法性能明显更高。基于神经网络的抽取式摘要方法主要分为序列标注方式和句子排序方式,其区别在于句子排序方式使用句子收益作为打分方式,考虑句子之间的相互关系。
序列标注方式
这种方法可以建模为序列标注任务进行处理,其核心想法是:为原文中的每一个句子打一个二分类标签(0或1),0代表该句不属于摘要,1代表该句属于摘要。最终摘要由所有标签为1的句子构成。
这种方法的关键在于获得句子的表示,即将句子编码为一个向量,根据该向量进行二分类任务,例如SummaRuNNer模型[48],使用双向GRU分别建模词语级别和句子级别的表示(模型如下图1所示)。蓝色部分为词语级别表示,红色部分为句子级别表示,对于每一个句子表示,有一个0、1标签输出,指示其是否是摘要。
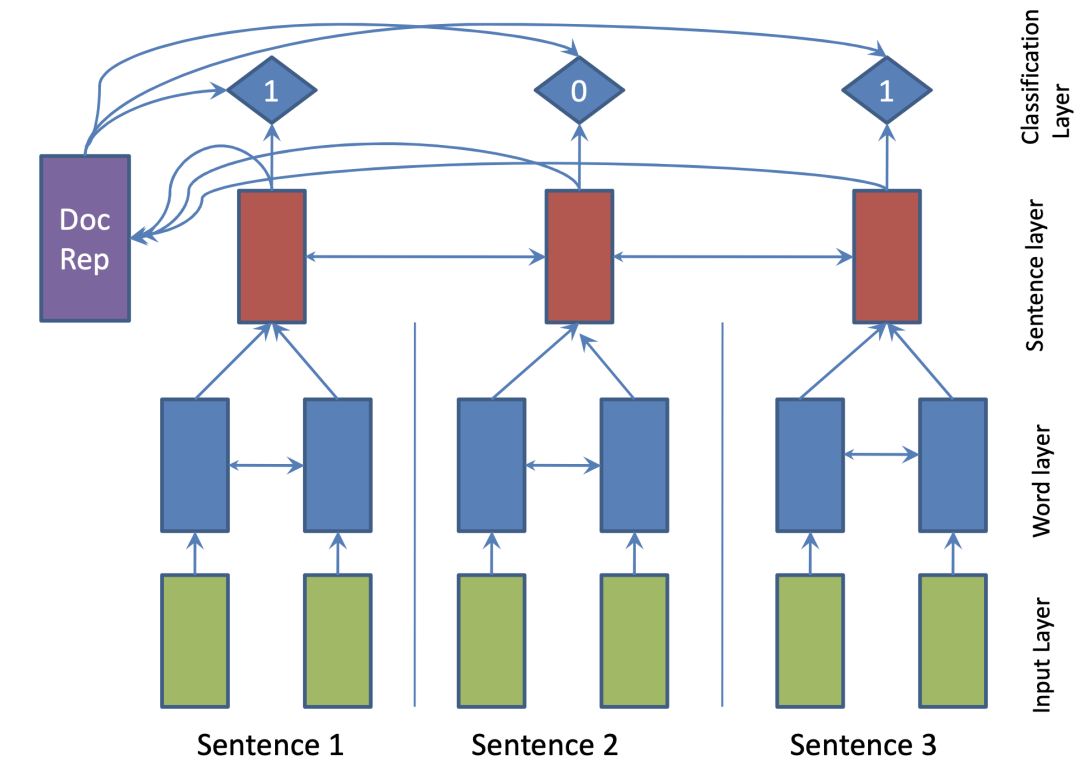
图1 SummaRuNNer模型结构
该模型的训练需要监督数据,现有数据集往往没有对应的句子级别的标签,可以通过启发式规则进行获取。具体方法为:首先选取原文中与标准摘要计算ROUGE得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合ROUGE得分增加,直至无法满足该条件。得到的候选摘要集合对应的句子设为1标签,其余为0标签。
句子排序方式
抽取式摘要还可以建模为句子排序任务,与序列标注任务的不同点在于,序列标注对于每一个句子表示打一个0、1标签,而句子排序任务则是针对每个句子输出其是否是摘要句的概率,最终依据概率,选取Top K个句子作为最终摘要。虽然任务建模方式(最终选取摘要方式)不同,但是其核心关注点都是对于句子表示的建模。
序列标注方式的模型在得到句子的表示以后对于句子进行打分,这就造成了打分与选择是分离的,先打分,后根据得分进行选择,没有利用到句子之间的关系。NeuSUM[49]提出了一种新的打分方式,使用句子收益作为打分方式,考虑到了句子之间的相互关系。其模型NeuSUM如下图2所示:
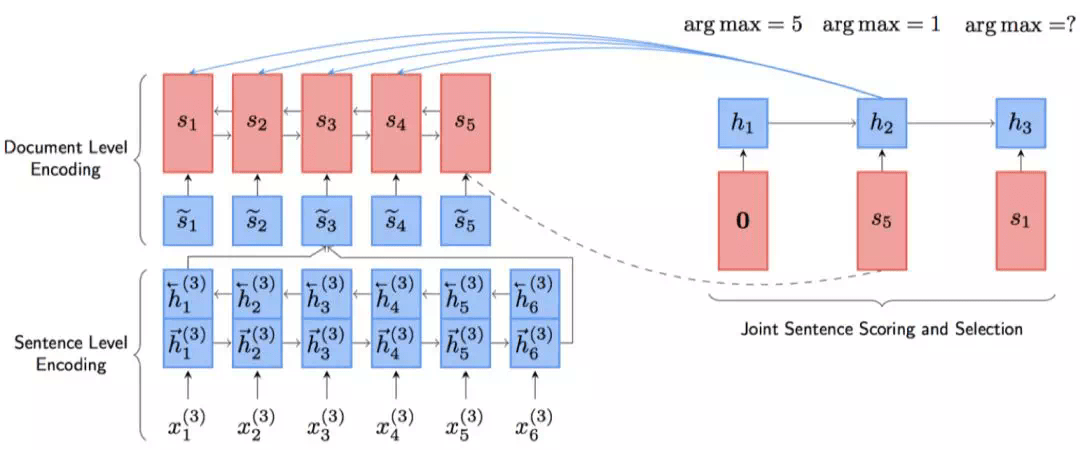
图2 NeuSUM模型结构
句子编码部分与之前基本相同。打分和抽取部分使用单向GRU和双层MLP完成。单向GRU用于记录过去抽取句子的情况,双层MLP用于打分,如下公式所示:
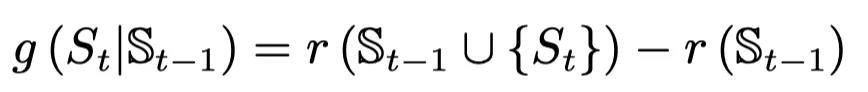
2.2 生成式摘要模型
抽取式摘要在语法、句法上有一定的保证,但是也面临了一定的问题,例如:内容选择错误、连贯性差、灵活性差等问题。生成式摘要允许摘要中包含新的词语或短语,灵活性较高。随着近几年神经网络模型的发展,序列到序列(Seq2Seq)模型被广泛地用于生成式摘要任务,并取得一定的成果。下面介绍生成式摘要模型中经典的Pointer-Generator[50]模型和基于要点的生成式摘要模型Leader+Writer[4]。
Pointer-Generator模型
仅使用Seq2Seq来完成生成式摘要存在如下问题:
- 未登录词问题(OOV);
- 重复生成问题。
Pointer-Generator[50]在基于注意力机制的Seq2Seq基础上增加了Copy和Coverage机制,有效地缓解了上述问题。其模型结构如下图3所示:
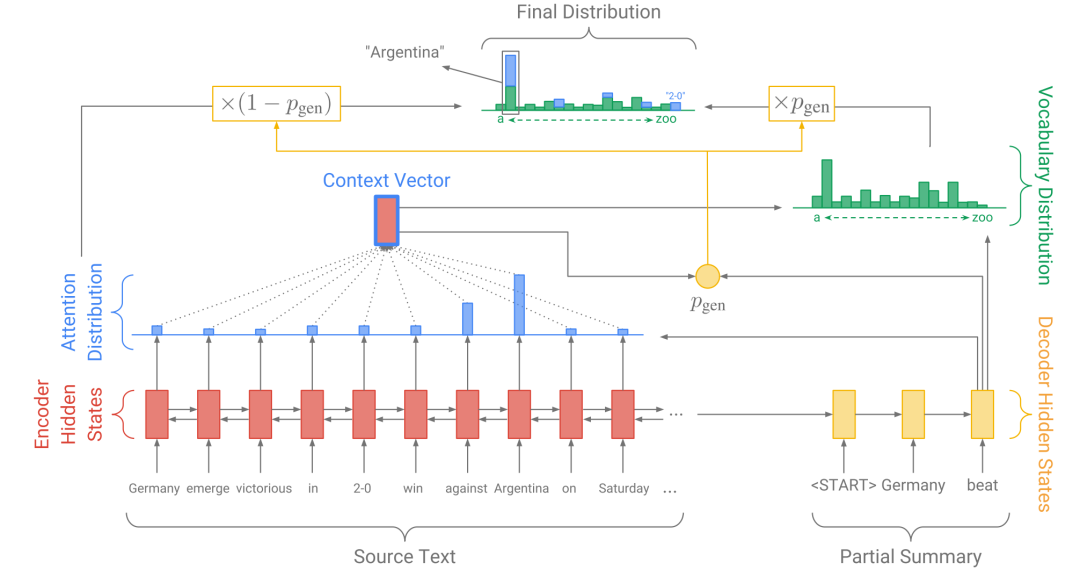
图3 Pointer-Generator 模型结构
该模型基于注意力机制的Seq2Seq模型,使用每一步解码的隐层状态与编码器的隐层状态计算权重,最终得到Context向量,利用Context向量和解码器隐层状态计算输出概率。
两个创新
- Copy机制: 在解码的每一步计算拷贝或生成的概率,因为词表是固定的,该机制可以选择从原文中拷贝词语到摘要中,有效地缓解了未登录词(OOV)的问题。
- Coverage机制: 在解码的每一步考虑之前步的注意力权重,结合Coverage损失, 避免继续考虑已经获得高权重的部分。该机制可以有效缓解生成重复的问题。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢