
文本分类是自然语言处理中最基本的任务。由于深度学习的空前成功,过去十年中该领域的研究激增。已有的文献提出了许多方法,数据集和评估指标,从而需要对这些内容进行全面的总结。本文回顾1961年至2020年的文本分类方法,重点是从浅层学习到深度学习的模型。根据所涉及的文本以及用于特征提取和分类的模型创建用于文本分类的分类法。然后,详细讨论这些类别中的每一个类别,涉及支持预测测试的技术发展和基准数据集。并提供了不同技术之间的全面比较,确定了各种评估指标的优缺点。最后,通过总结关键含义,未来的研究方向以及研究领域面临的挑战进行总结。
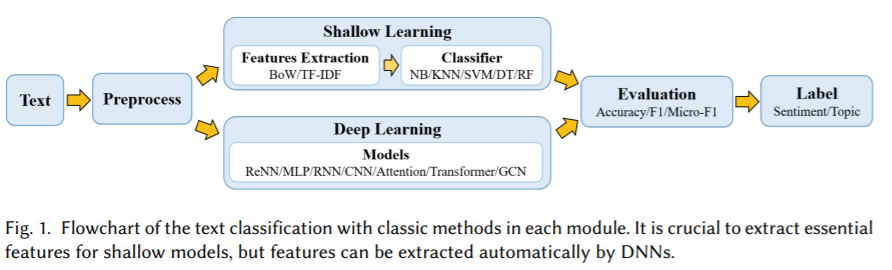
文本分类流程。在许多NLP应用中,文本分类-为文本指定预定义标签的过程-是一项基础而重要的任务。文本分类的主要流程:首先是预处理模型的文本数据。浅层学习模型通常需要通过人工方法获得良好的样本特征,然后使用经典的机器学习算法对其进行分类。因此,该方法的有效性在很大程度上受到特征提取的限制。但是,与浅层模型不同,深度学习通过学习一组非线性变换将特征工程直接集成到输出中,从而将特征工程集成到模型拟合过程中。
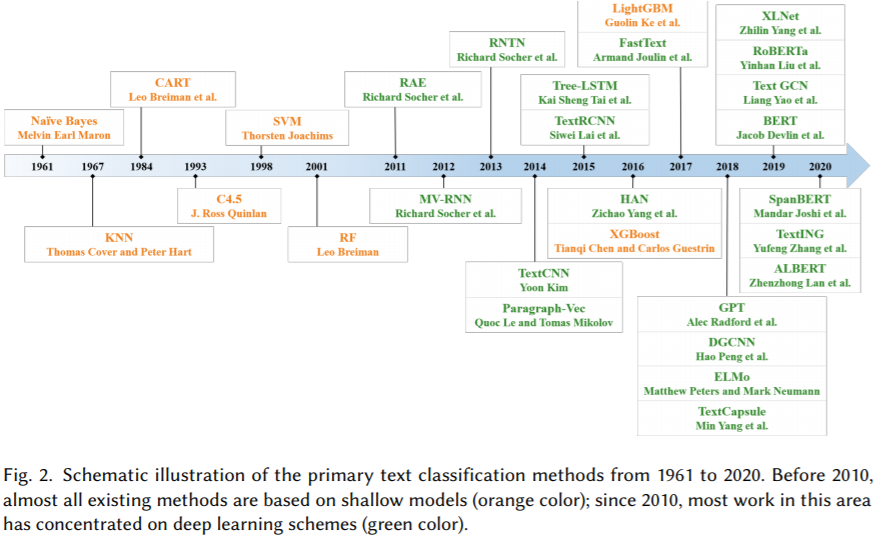
 文本分类发展历程。主要文本分类方法的示意图如图2所示。从1960年代到2010年代,基于浅层学习的文本分类模型占主导地位。浅层学习意味着基于统计的模型,例如朴素贝叶斯(NB),K近邻(KNN)和支持向量机(SVM)。与早期的基于规则的方法相比,该方法在准确性和稳定性方面具有明显的优势。但是,这些方法仍然需要进行功能设计,这既耗时又昂贵。此外,它们通常会忽略文本数据中的自然顺序结构或上下文信息,这使学习单词的语义信息变得困难。自2010年代以来,文本分类已逐渐从浅层学习模型变为深层学习模型。与基于浅层学习的方法相比,深度学习方法避免了人工设计规则和功能,并自动为文本挖掘提供了语义上有意义的表示形式。因此,大多数文本分类研究工作都基于DNN,DNN是数据驱动的方法,具有很高的计算复杂性。很少有研究专注于浅层学习模型来解决计算和数据的局限性。
文本分类发展历程。主要文本分类方法的示意图如图2所示。从1960年代到2010年代,基于浅层学习的文本分类模型占主导地位。浅层学习意味着基于统计的模型,例如朴素贝叶斯(NB),K近邻(KNN)和支持向量机(SVM)。与早期的基于规则的方法相比,该方法在准确性和稳定性方面具有明显的优势。但是,这些方法仍然需要进行功能设计,这既耗时又昂贵。此外,它们通常会忽略文本数据中的自然顺序结构或上下文信息,这使学习单词的语义信息变得困难。自2010年代以来,文本分类已逐渐从浅层学习模型变为深层学习模型。与基于浅层学习的方法相比,深度学习方法避免了人工设计规则和功能,并自动为文本挖掘提供了语义上有意义的表示形式。因此,大多数文本分类研究工作都基于DNN,DNN是数据驱动的方法,具有很高的计算复杂性。很少有研究专注于浅层学习模型来解决计算和数据的局限性。
 技术挑战。文本分类-作为有效的信息检索和挖掘技术-在管理文本数据中起着至关重要的作用。它使用NLP,数据挖掘,机器学习和其他技术来自动分类和发现不同的文本类型。文本分类将多种类型的文本作为输入,并且文本由预训练模型表示为矢量。然后将向量馈送到DNN中进行训练,直到达到终止条件为止,最后,下游任务验证了训练模型的性能。现有的模型已经显示出它们在文本分类中的有用性,但是仍有许多可能的改进需要探索。尽管一些新的文本分类模型反复擦写了大多数分类任务的准确性指标,但它无法指示模型是否像人类一样从语义层面“理解”文本。此外,随着噪声样本的出现,小的样本噪声可能导致决策置信度发生实质性变化,甚至导致决策逆转。因此,需要在实践中证明该模型的语义表示能力和鲁棒性。此外,由词向量表示的预训练语义表示模型通常可以提高下游NLP任务的性能。关于上下文无关单词向量的传输策略的现有研究仍是相对初步的。因此,我们从数据,模型和性能的角度得出结论,文本分类主要面临以下挑战:
数据层面:对于文本分类任务,无论是浅层学习还是深度学习方法,数据对于模型性能都是必不可少的。研究的文本数据主要包括多章,短文本,跨语言,多标签,少样本文本。对于这些数据的特征,现有的技术挑战如下:
Zero-shot/Few-shot learning。当前的深度学习模型过于依赖大量标记数据。这些模型的性能在零镜头或少镜头学习中受到显着影响。
外部知识。我们都知道,输入的有益信息越多,DNN的性能就越好。因此,认为添加外部知识(知识库或知识图)是提高模型性能的有效途径。然而,如何添加以及添加什么仍然是一个挑战。
多标签文本分类任务。多标签文本分类需要充分考虑标签之间的语义关系,并且模型的嵌入和编码是有损压缩的过程。因此,如何减少训练过程中层次语义的丢失以及如何保留丰富而复杂的文档语义信息仍然是一个亟待解决的问题。
具有许多术语词汇的特殊领域。特定领域的文本(例如金融和医学文本)包含许多特定的单词或领域专家,可理解的语,缩写等,这使现有的预训练单词向量难以使用。
模型层面:现有的浅层和深度学习模型的大部分结构都被尝试用于文本分类,包括集成方法。BERT学习了一种语言表示法,可以用来对许多NLP任务进行微调。主要的方法是增加数据,提高计算能力和设计训练程序,以获得更好的结果如何在数据和计算资源和预测性能之间权衡是值得研究的。
性能评估层面:浅层模型和深层模型可以在大多数文本分类任务中取得良好的性能,但是需要提高其结果的抗干扰能力。如何实现对深度模型的解释也是一个技术挑战。
模型的语义鲁棒性。近年来,研究人员设计了许多模型来增强文本分类模型的准确性。但是,如果数据集中有一些对抗性样本,则模型的性能会大大降低。因此,如何提高模型的鲁棒性是当前研究的热点和挑战。
模型的可解释性。DNN在特征提取和语义挖掘方面具有独特的优势,并且已经完成了出色的文本分类任务。但是,深度学习是一个黑盒模型,训练过程难以重现,隐式语义和输出可解释性很差。它对模型进行了改进和优化,丢失了明确的准则。此外,我们无法准确解释为什么该模型可以提高性能。
论文链接:https://arxiv.org/abs/2008.00364
code:https://github.com/RobertIBM/--A-Survey-on-Text-Classification-From-Shallow-to-Deep-Learning
csdn分享:https://blog.csdn.net/Liberty_P/article/details/107960976
计算机视觉分享:https://mp.weixin.qq.com/s/CMMyZteyXjOkMZURBkQJtQ
专知分享:https://mp.weixin.qq.com/s/yqARcPx4eIof5LQDLvdZew
机器之心分享:https://mp.weixin.qq.com/s/raffxivHBUi81kRkOotIZg
技术挑战。文本分类-作为有效的信息检索和挖掘技术-在管理文本数据中起着至关重要的作用。它使用NLP,数据挖掘,机器学习和其他技术来自动分类和发现不同的文本类型。文本分类将多种类型的文本作为输入,并且文本由预训练模型表示为矢量。然后将向量馈送到DNN中进行训练,直到达到终止条件为止,最后,下游任务验证了训练模型的性能。现有的模型已经显示出它们在文本分类中的有用性,但是仍有许多可能的改进需要探索。尽管一些新的文本分类模型反复擦写了大多数分类任务的准确性指标,但它无法指示模型是否像人类一样从语义层面“理解”文本。此外,随着噪声样本的出现,小的样本噪声可能导致决策置信度发生实质性变化,甚至导致决策逆转。因此,需要在实践中证明该模型的语义表示能力和鲁棒性。此外,由词向量表示的预训练语义表示模型通常可以提高下游NLP任务的性能。关于上下文无关单词向量的传输策略的现有研究仍是相对初步的。因此,我们从数据,模型和性能的角度得出结论,文本分类主要面临以下挑战:
数据层面:对于文本分类任务,无论是浅层学习还是深度学习方法,数据对于模型性能都是必不可少的。研究的文本数据主要包括多章,短文本,跨语言,多标签,少样本文本。对于这些数据的特征,现有的技术挑战如下:
Zero-shot/Few-shot learning。当前的深度学习模型过于依赖大量标记数据。这些模型的性能在零镜头或少镜头学习中受到显着影响。
外部知识。我们都知道,输入的有益信息越多,DNN的性能就越好。因此,认为添加外部知识(知识库或知识图)是提高模型性能的有效途径。然而,如何添加以及添加什么仍然是一个挑战。
多标签文本分类任务。多标签文本分类需要充分考虑标签之间的语义关系,并且模型的嵌入和编码是有损压缩的过程。因此,如何减少训练过程中层次语义的丢失以及如何保留丰富而复杂的文档语义信息仍然是一个亟待解决的问题。
具有许多术语词汇的特殊领域。特定领域的文本(例如金融和医学文本)包含许多特定的单词或领域专家,可理解的语,缩写等,这使现有的预训练单词向量难以使用。
模型层面:现有的浅层和深度学习模型的大部分结构都被尝试用于文本分类,包括集成方法。BERT学习了一种语言表示法,可以用来对许多NLP任务进行微调。主要的方法是增加数据,提高计算能力和设计训练程序,以获得更好的结果如何在数据和计算资源和预测性能之间权衡是值得研究的。
性能评估层面:浅层模型和深层模型可以在大多数文本分类任务中取得良好的性能,但是需要提高其结果的抗干扰能力。如何实现对深度模型的解释也是一个技术挑战。
模型的语义鲁棒性。近年来,研究人员设计了许多模型来增强文本分类模型的准确性。但是,如果数据集中有一些对抗性样本,则模型的性能会大大降低。因此,如何提高模型的鲁棒性是当前研究的热点和挑战。
模型的可解释性。DNN在特征提取和语义挖掘方面具有独特的优势,并且已经完成了出色的文本分类任务。但是,深度学习是一个黑盒模型,训练过程难以重现,隐式语义和输出可解释性很差。它对模型进行了改进和优化,丢失了明确的准则。此外,我们无法准确解释为什么该模型可以提高性能。
论文链接:https://arxiv.org/abs/2008.00364
code:https://github.com/RobertIBM/--A-Survey-on-Text-Classification-From-Shallow-to-Deep-Learning
csdn分享:https://blog.csdn.net/Liberty_P/article/details/107960976
计算机视觉分享:https://mp.weixin.qq.com/s/CMMyZteyXjOkMZURBkQJtQ
专知分享:https://mp.weixin.qq.com/s/yqARcPx4eIof5LQDLvdZew
机器之心分享:https://mp.weixin.qq.com/s/raffxivHBUi81kRkOotIZg
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢