标题:360、清华|Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework(Zero和R2D2:一种大规模的中文跨模态基准测试和视觉语言框架)
作者:Chunyu Xie, Heng Ca, Xiangyang Ji, Yafeng Deng等
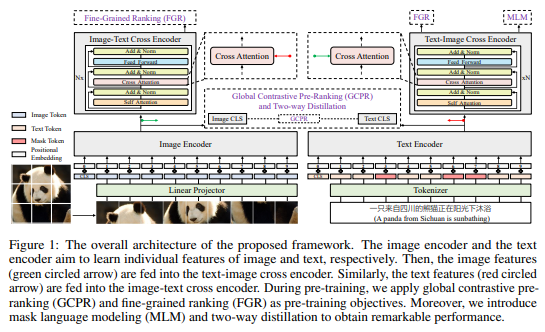
简介:大规模数据集上的视觉语言预训练 (VLP) 已显示出卓越性能在各种下游任务上的表现。完整且公平的基准(即包括大规模的预训练数据集和各种下游任务)对于VLP至关重要。然英语语料库有很多基准,但构建一个VLP与其他语言(如中文)的丰富基准测试仍然是一个关键问题。为此,作者构建了一个大规模的中文跨模式基准,称为Zero,以公平地比较VLP模型。作者针对下游任务发布了两个预训练数据集和五个微调数据集。除此之外,作者还提出了一种新颖的预训练框架,即预排序+排序,用于跨模态学习。具体来说,作者应用全局对比预排序分别学习图像和文本的单个表示形式。然后作者通过图像-文本交叉以细粒度的排序方式融合表示编码器和文本图像交叉编码器,进一步提升能力该模型,作者提出了一种由目标引导组成的双向蒸馏策略蒸馏和功能引导蒸馏,命名为R2D2。作者在四个公共跨模态数据集上和五个下游数据集实现了最先进的性能。在进行零样本任务时Flickr30k-CN、COCO-CN 和 MUGE、R2D2 在 2.5 亿个数据集上进行预训练,与最先进的技术相比,平均召回率分别提高了 4.7%、5.4% 和 6.3%。
代码下载:https://github.com/yuxie11/R2D2
论文下载:https://arxiv.org/pdf/2205.03860v3.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢