
本文分享论文『CoCa: Contrastive Captioners are Image-Text Foundation Models』,Google Research提出超强预训练模型CoCa,在ImageNet上微调Top-1准确率达91%!在多个下游任务上SOTA!
详细信息如下:

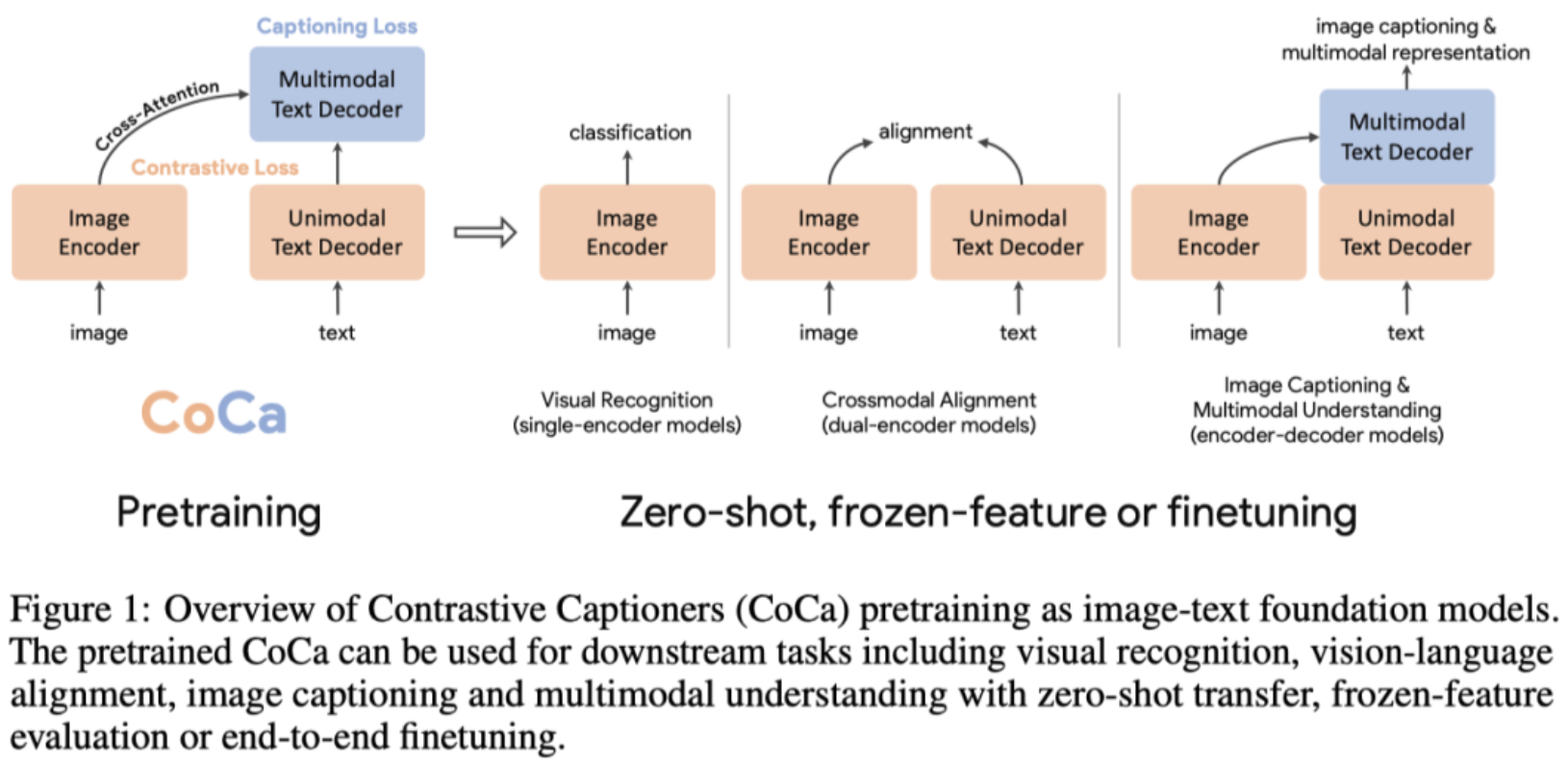
探索大规模预训练基础模型在计算机视觉中具有重要意义,因为这些模型可以快速转移到许多下游任务中。本文提出了对比字幕(Contrastive Captioner,CoCa)模型,它将图像文本编码器-解码器基础模型与对比损失和字幕损失结合起来进行预训练,从而从CLIP等对比方法和SimVLM等生成方法中吸收两种模型的长处。与所有解码器层都attend到编码器输出的标准编码器-解码器Transformer不同,CoCa省略了前一半解码器层中的交叉注意来编码unimodal文本表示,并将交叉注意力图像编码器的其余解码器层级联以进行multimodal图像文本表示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢