
作者:Nayeon Lee , Wei Ping , Peng Xu , Mostofa Patwary ,等
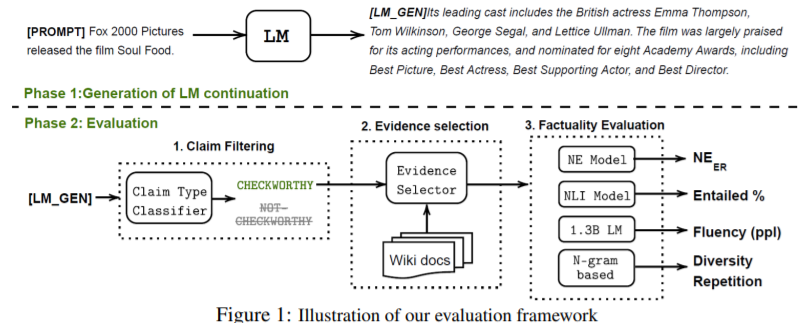
简介:针对预训练语言模型 (LM) 开放式文本生成:本文研究提高大规模 LM 的事实准确性。作者设计了 FactualityPrompts 测试集和指标来衡量 LMs的真实性。在此基础上,作者研究了参数大小从 126M 到 530B 的 LMs 的事实准确性。有趣的是,作者发现较大的 LM 比较小LM的更符合事实,尽管之前的一项研究表明,较大的 LM 存在误解可能不太真实。此外,开放式文本生成中流行的采样算法(例如,top-p)可能会由于在每个采样步骤中引入的“均匀随机性”而损害事实性。作者提出了事实核采样算法,该算法动态地适应随机性以提高生成的真实性,同时保持质量。此外,作者分析了标准训练方法在从事实文本语料库(例如,维基百科)中学习实体之间的正确关联方面的低效率。作者提出了一种事实性增强训练方法,该方法使用 TopicPrefix 更好地了解事实和句子完成作为训练目标,可以大大减少事实错误。

论文下载:https://arxiv.org/pdf/2206.04624.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢