
ACL 2022华为发表了一篇论文:Enabling Multimodal Generation on CLIP via Vision-Language Knowledge Distillation(VLKD)。这篇文章将CLIP的跨模态能力以及预训练语言模型的BART的生成能力进行联合,实现了对CLIP模型text encoder的加强,在VQA、Caption等多个任务上都取得非常好的效果。

论文链接:
https://arxiv.org/abs/2203.06386
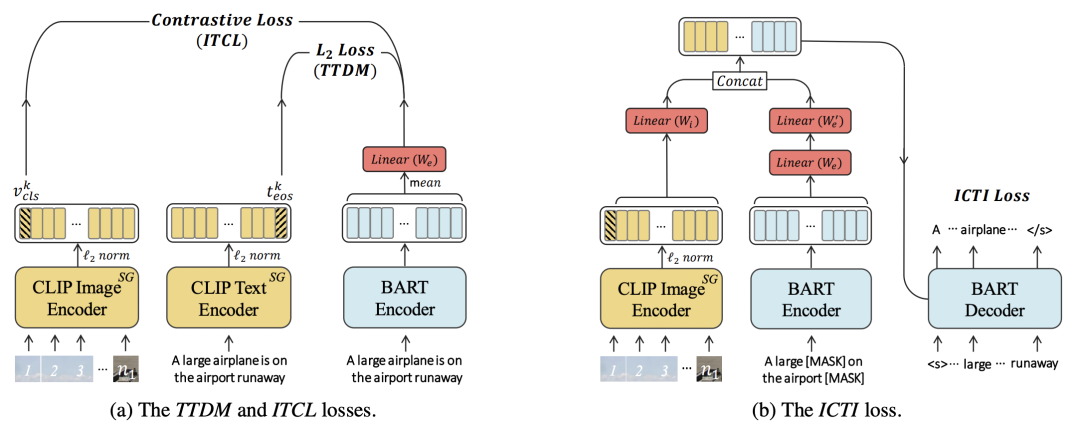
VLKD的整体结构非常简单,如下图所示,将原来CLIP模型中的text encoder替换成预训练BART的encoder + decoder,通过知识蒸馏的方式让BART的encoder和decoder学到CLIP中的跨模态知识。这里的跨模态知识,指的是让BART能够处理图像信息,借助CLIP中已经将图像和文本的表示映射到同一空间的能力,将BART对文本的表示也映射到这一空间。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢