
【标题】Receding Horizon Inverse Reinforcement Learning
【作者团队】Yiqing Xu, Wei Gao, David Hsu
【发表日期】2022.6.9
【论文链接】https://arxiv.org/pdf/2206.04477.pdf
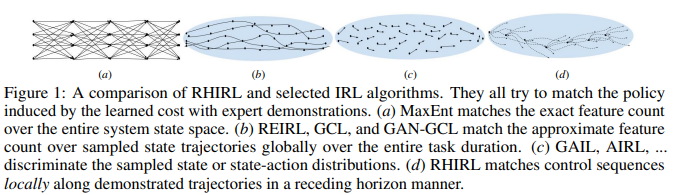
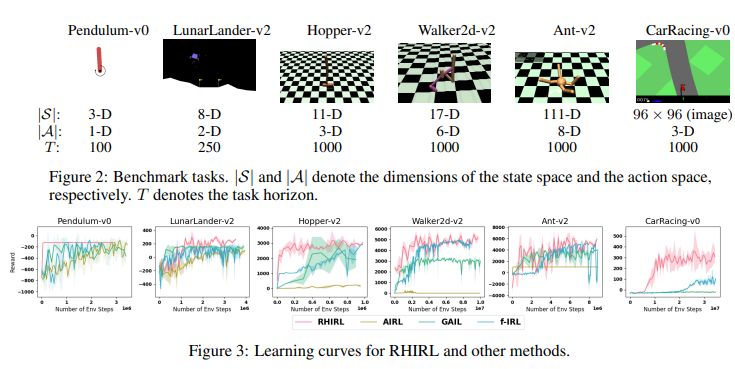
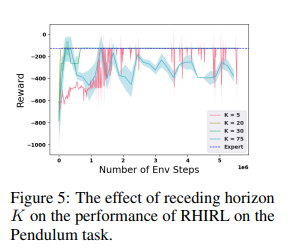
【推荐理由】逆强化学习 (IRL) 旨在推断成本函数,以解释专家演示的基本目标和偏好。本文介绍了滚动时域逆强化学习 (RHIRL),这是一种新的 IRL 算法,用于具有黑箱动态模型的高维、嘈杂、连续系统。RHIRL 解决了 IRL 的两个关键挑战:可扩展性和鲁棒性。为处理高维连续系统,RHIRL 将诱导出的最优轨迹与本地专家演示相匹配,并以后退的方式将本地解决方案“缝合”在一起以了解成本;从而避免了“维度诅咒”。这与早期的算法形成鲜明对比,这些算法与整个高维状态空间的全球专家演示相匹配。为了对不完美的专家演示和系统控制噪声具有鲁棒性,RHIRL 在温和条件下学习了一个与系统动力学“分离”的状态相关成本函数。基准任务实验表明,在大多数情况下,RHIRL 优于几种领先的 IRL 算法。我并证明了 RHIRL 的累积误差随任务持续时间线性增长。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢