

论文链接:https://arxiv.org/abs/2104.08271
项目链接:https://github.com/albanie/collaborative-experts
导读
近年来,通过对视频和音频数据集进行大规模预训练来构建强大的视频编码器,文本视频检索任务取得了长足的进展。相比之下,尽管具有天然的对称性,但开发大规模语言预训练的有效算法的设计仍有待探索。在这项工作中,作者首先研究了此类算法的设计,并提出了一种新的广义蒸馏方法TEACHTEXT,该方法利用来自多个文本编码器的互补线索为检索模型提供增强的监控信号。此外,作者将本文的方法扩展到视频端,并表明本文的方法可以在不影响性能的情况下有效减少测试时使用的模态数量。本文的方法大大提高了几个视频检索基准的技术水平,并且在测试时不增加计算开销。最后,作者展示了本文的方法在消除检索数据集噪声方面的有效应用。
贡献
这项工作的重点是文本视频检索—识别候选库中的哪个视频与描述其内容的自然语言查询最匹配。视频搜索在野生动物监测、安全、工业过程监测和娱乐等领域有着广泛的应用。此外,随着人类继续以越来越大的规模制作视频,有效执行此类搜索的能力对YouTube等视频托管平台具有至关重要的商业意义。
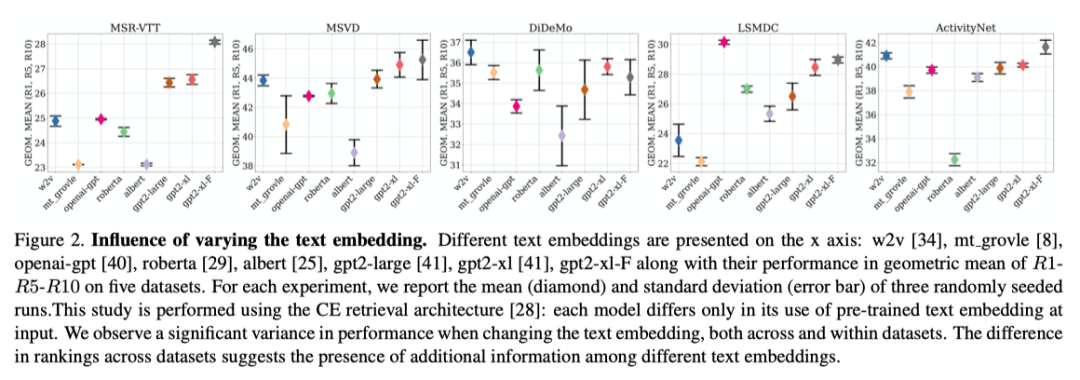
最近提出的检索方法的一个中心主题是研究如何最好地使用多个视频模态来提升性能。特别是,基于mixtures-of-experts和多模Transformer的架构显示了在相关任务中使用不同的预训练模型集作为训练和测试期间视频编码的基础的好处。
在这项工作中,作者探索是否可以通过利用在大规模书面语料库上学习的多个文本嵌入来获得相应的收益。与使用多种模态和预训练任务的视频嵌入不同,文本嵌入集合之间存在足够的多样性以实现性能提升的现象不太明显。事实上,本文的灵感来自于对一系列检索基准中不同文本嵌入的性能的调查,如上图所示。作者不仅观察到文本嵌入的性能差异很大,而且它们的排名也不一致,这有力地支持了使用多个文本嵌入的想法。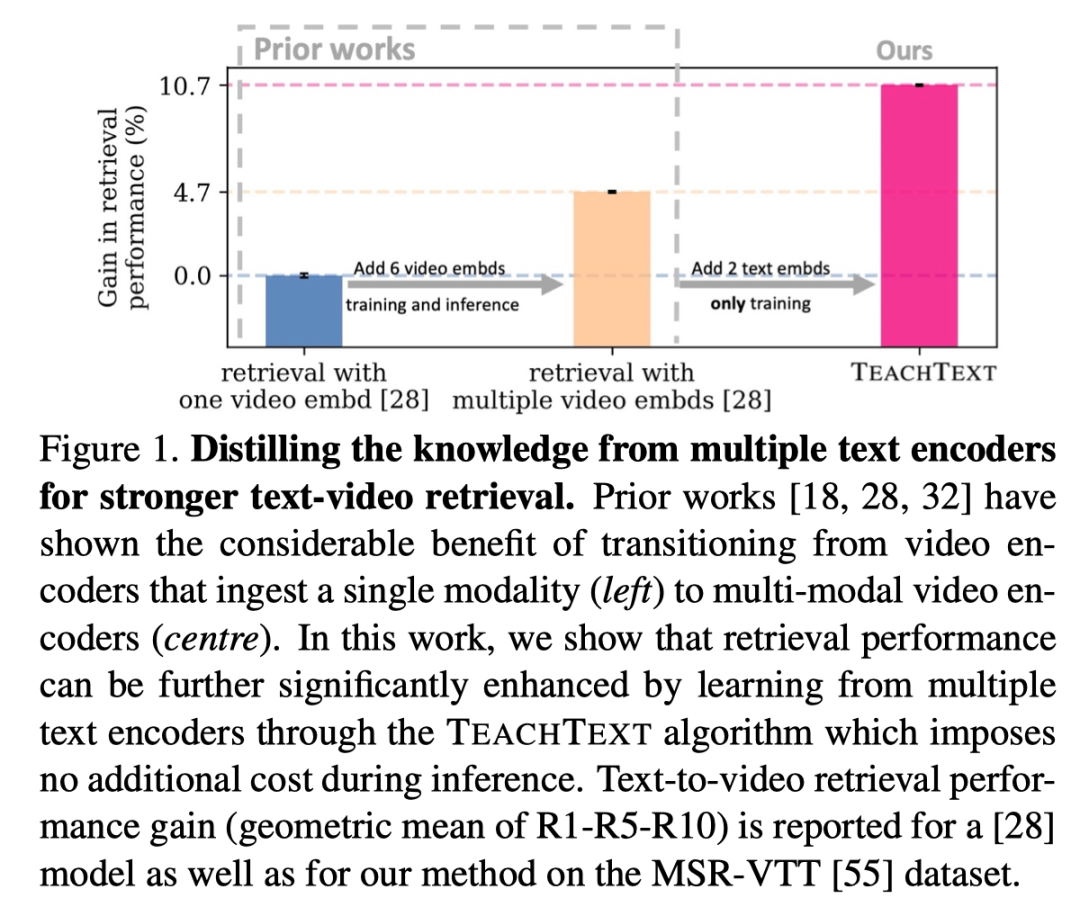
基于这一发现,作者提出了一个简单的算法T EACH T EXT,以有效地利用这些文本嵌入的知识。本文的方法需要一个“学生”模型从一个或多个“教师”检索模型学习,通过将其文本-视频相似度矩阵提取到增强的监控信号中来访问不同的文本嵌入。如上图所示,TEACHTEXT都能够提供显著的性能增益。此外,该增益与向视频编码器添加更多视频模态的增益是互补的。重要的是,与添加视频模态不同,该方法在推断期间不会产生额外的计算成本。
本文的主要贡献可以总结如下:
- 作者提出了T EACHT EXT算法,该算法利用了多个文本编码器提供的附加信息;
- 作者表明,直接学习联合查询视频嵌入之间的检索相似度矩阵是该任务的一种有效的广义蒸馏技术;
- 作者展示了本文的方法在文本视频检索任务中从现代训练数据集中消除噪声的应用;
- 在六个文本视频检索基准上,本文方法实现了SOTA性能。
方法
3.1. 问题描述
设D={(vi,ci),i=1,...,n}是成对视频和字幕的数据集。对于每个视频,可以访问视频嵌入(称为“专家”)的集合xi,该集合是使用预训练视频编码器(VE)从视频vi的各种模态中提取的,此外,对于每个字幕/查询ci,还可以使用文本嵌入ti(使用文本编码器TE提取)。
文本视频检索任务的目标是学习一个模型M,该模型将高相似度值、分配给对应(即i=j)的视频和文本嵌入的配对(xi,tj),反之则为低相似度。作者将模型参数化为在共享空间中生成联合嵌入的双编码器,以便可以直接比较它们,其中F和Q分别表示学习的视频和文本编码器。为了视频和文本编码器执行检索任务,作者采用contrastive ranking loss:
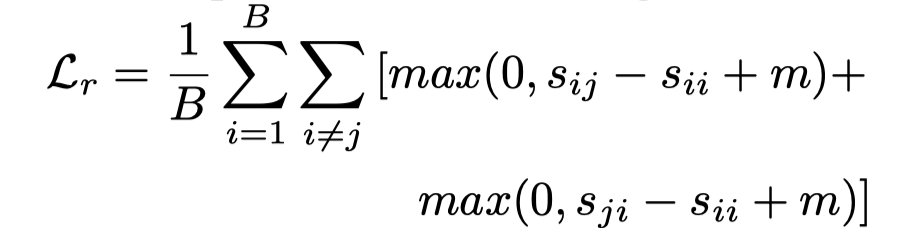
其中,B表示训练期间使用的batch大小,是编码视频F()和查询Q()之间的相似性得分,而m是margin。
本文方法背后的关键思想是学习一个检索模型M,该模型除了上面描述的损失之外,还可以访问由一组经过预训练的“教师”检索模型提供的信息,这些模型在同一任务上进行了训练,但吸收了不同的文本嵌入。
3.2. TEACHT EXT algorithm
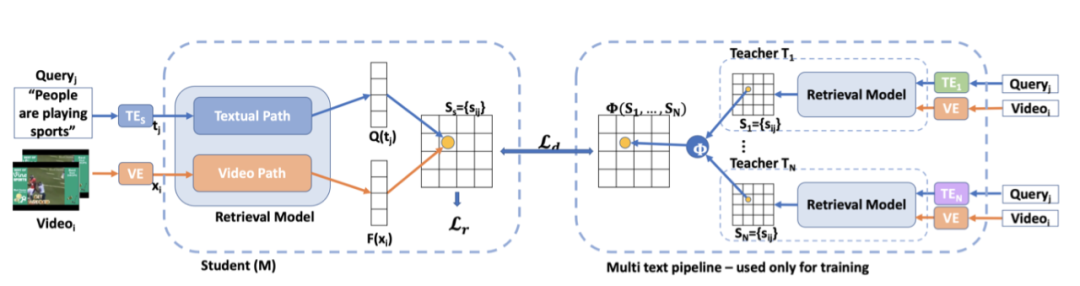
为了提高模型M的检索性能,本文提出了T-EACH-T-EXT算法,该算法旨在利用来自多个文本嵌入的线索。上图概述了的方本文法。首先了一组教师模型用于使用该方法的文本视频检索任务。教师共享相同的结果,但每个模型使用不同的文本嵌入作为输入。
在第二阶段,教师的参数被冻结。然后,作者对一个batch的B对视频和字幕进行采样,为每个教师计算相应的相似度矩阵(上图右侧)。然后将这N个相似矩阵聚合,形成一个单一的监督相似矩阵(上图右中)。
同时,这个batch视频和字幕同样由学生模型M处理,M生成另一个相似矩阵。最后,除了标准检索损失外,蒸馏损失促使靠近,算法如下所示:
在推理过程中,教师模型被丢弃,学生模型M只需要单个文本嵌入。接下来,作者给出了用于相似矩阵学习的蒸馏损失的详细信息。
3.3. Learning the similarity matrix
检索任务的本质是创建一个能够在视频和文本/查询之间建立跨模态对应关系的模型。为匹配的视频文本分配高相似度值,否则为低相似度值。这使得相似度矩阵成为有关模型所持有知识的丰富信息源。
为了能够将知识从教师传递给学生,作者鼓励学生生成一个相似度矩阵,该矩阵与教师生成的相似度矩阵的总和相匹配。通过这种方式,模型传递了有关文本和视频通信的信息,而无需严格要求学生生成与教师完全相同的嵌入。为此,作者将相似矩阵蒸馏损失定义为: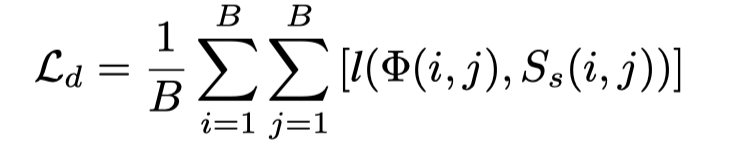
其中,B表示batch大小,表示教师相似度矩阵的集合,表示学生的相似度矩阵。最后,受其他蒸馏工作的启发,l表示Huber损失,定义为: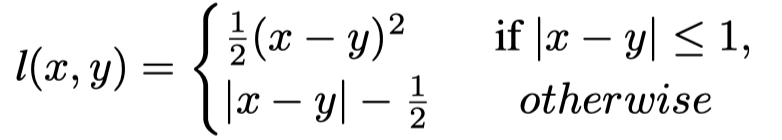
作者研究了几种形式的聚集函数,发现简单的元素平均值,在实践中效果良好。
3.4. Student model
本文的方法的一个关键优势是,它对学生和教师的网络形式不可知,因此学生(和教师)可以使用当前文献中的任何方法。作者使用三种不同的最新作品MoEE、CE、MMT作为学生和教师的基础架构来测试本文的T EACH T EXT算法。所有这些工作都采用了多模态视频编码器来完成文本视频检索任务。
3.5. Teacher models
教师模型使用与学生模型相同的结构。具体而言,作者创建了一个多个教师池,每个教师使用不同的预训练文本嵌入作为输入。本文考虑的候选文本嵌入有:mt_grovle、openai-gpt、gpt2-large、gpt2xl、w2v。因此,本文得到了一组由五个模型组成的教师。
3.6. Training and implementation details
为了训练最终的学生模型,作者将检索损失和提出的蒸馏损失结合起来。本文的模型使用Adam优化器在Pytorch中进行训练。T EACHT EXT不会向最终模型添加任何额外的可训练参数或模态。此外,当使用T EACH T EXT训练学生时,只添加额外的损失项,所有其他超参数保持不变。
实验
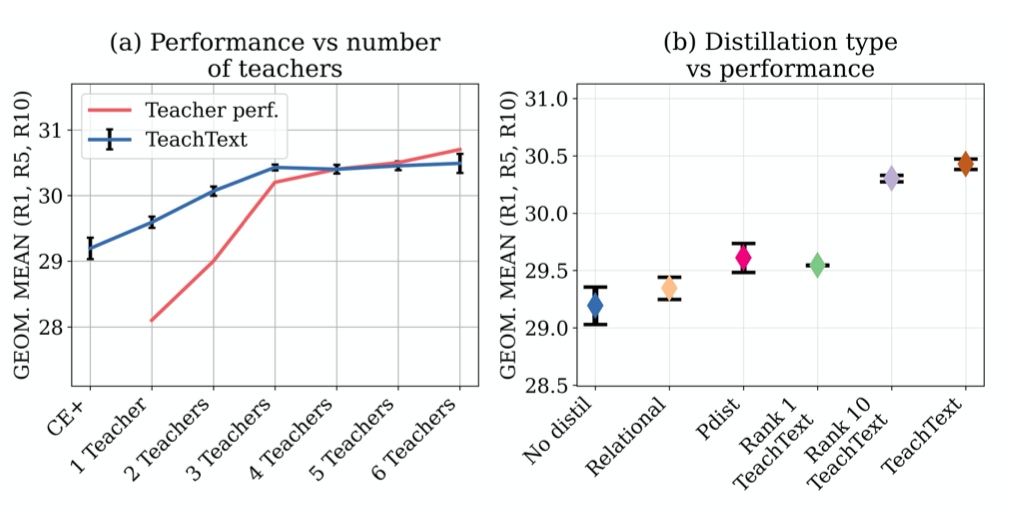
上图(a)展示了不同教师数量对实验结果的影响,上图展示了蒸馏类型对实验结果的影响。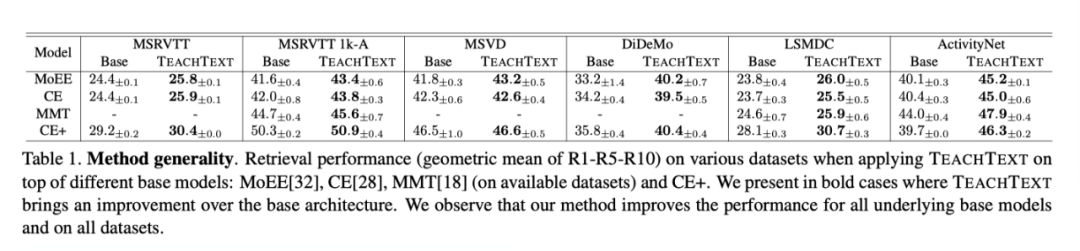
上表展示了本文方法在不同数据集和base模型上的实验结果,可以看出本文方法具有很强的泛化性。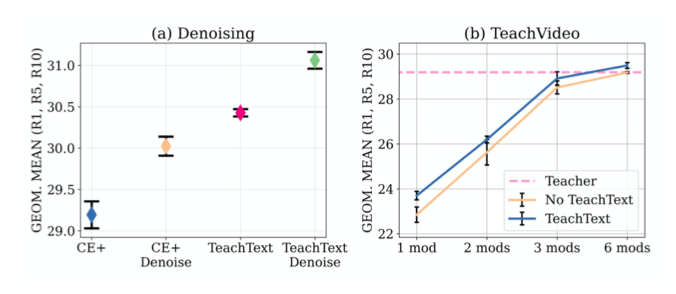
如上图a所示,在每个视频都有多个字幕的数据集中,本文的方法可以在不从训练中删除视频本身的情况下删除有噪声的字幕。上图b展示了采用视频中不同模态数量的实验结果。
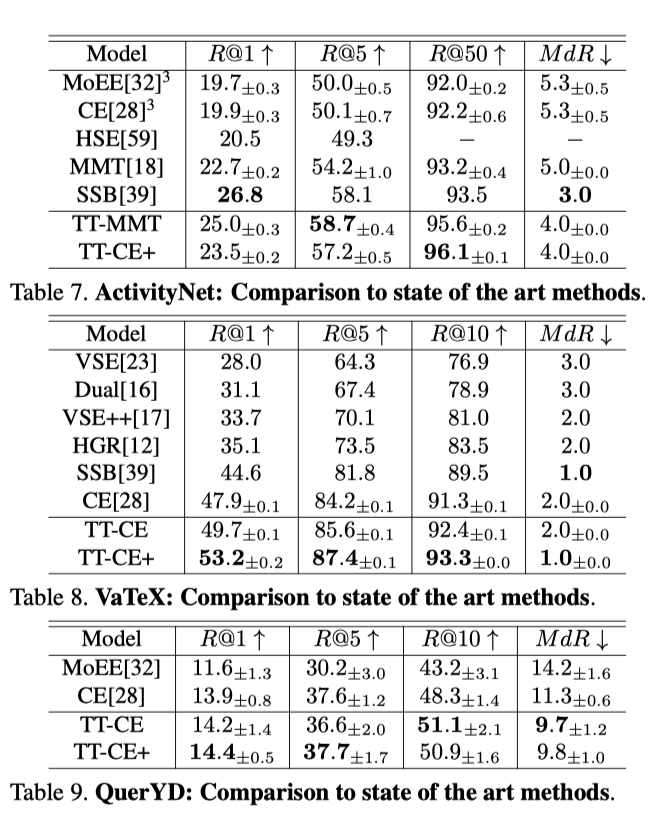
上表展示了本文方法在不同数据集上和SOTA方法的对比结果。
本文提出了一种新的文本视频检索算法T EACH T EXT。作者使用teacher-student模式,学生学习利用一个或多个教师提供的额外信息,共享网络架构,但每个教师在输入时使用不同的预训练文本嵌入。通过这种方式,作者在六个基准上取得了SOTA的成果。最后,作者提出了一个应用本文的方法去噪视频检索数据集。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢