
IFRNet: Intermediate Feature Refine Network for Efficient Frame Interpolation

论文:https://arxiv.org/abs/2205.14620
代码:https://github.com/ltkong218/ifrnet
一、摘要
目前流行的视频插帧算法通常依赖于复杂的网络结构,其具有大量的模型参数与较高的推理延迟,这限制了它们在大量实时应用中的使用。在这篇论文中,我们新发明了一个高效的只包含一个encoder-decoder结构的视频插帧网络称为IFRNet,以实现快速的中间帧合成。它首先对输入的两帧图像提取特征金字塔,然后联合refine双向中间光流场和一个具有较强表示能力的中间特征,直到恢复到输入分辨率并得到想要的输出。这个逐渐refine的中间特征不仅能够促进中间光流估计,而且能够补偿缺失的纹理细节,使得所提出的IFRNet不需要额外的纹理合成网或refinement模块。为了充分释放它的潜能,我们进一步提出一个新颖的面向任务的光流蒸馏损失函数来使得网络集中注意力学习对插帧有益的运动信息。与此同时,一个新的几何一致性正则化项被施加到逐渐refine的中间特征来保持其较好的结构布局。在多个公认的视频插帧评测数据集实验中,所提出的IFRNet和相关优化算法展现出了state-of-the-art的插帧精度与可视化效果,同时具有极快的推理速度。
二、研究背景
目前取得SOTA结果的插帧方法大都采用基于光流的方案,因为光流可以显示地描述逐像素的运动和对应关系,这在大运动场景中尤为重要。我们将已有的基于光流的插帧方法按照encoder-decoder的功能进行了如下分类
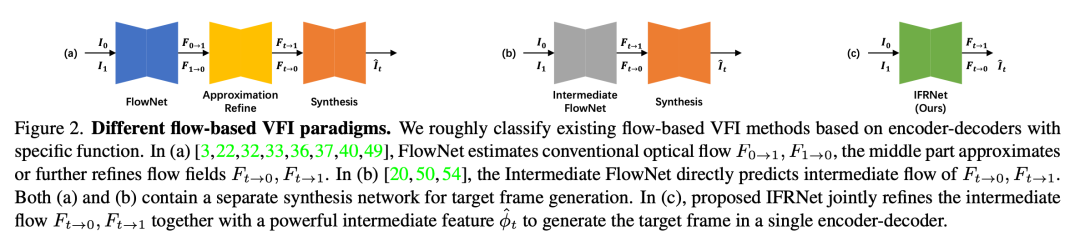
图(a),光流网FlowNet估计传统光流,中间部分encoder-decoder近似或进一步refine中间光流。图(b),中间光流网直接估计中间光流。(a) 和 (b) 都包含一个独立的合成网来对光流warp的输入帧以及特征进行编码,并合成目标帧纹理。尽管以上方案已经成为基于光流的主流解决思路,但其仍面临如下问题:
1.已有基于光流的插帧算法将中间光流估计与中间帧特征合成分开到多个独立的encoder-decoder网络,这使得这两个重要成分缺乏紧凑的交互,并妨碍了它们的相互提升。
2.已有基于光流的插帧算法采用多个encoder-decoder级联的结构,这使得它们往往具有较大的推理延迟与计算复杂度。
三、模型方法
为了解决以上问题,我们首次将上述分开的中间光流估计与中间特征重建过程合并到一个encoder-decoder网络,并达到了更紧凑的模型结构与更快的推理速度,如图(c)所示。
- 网络结构
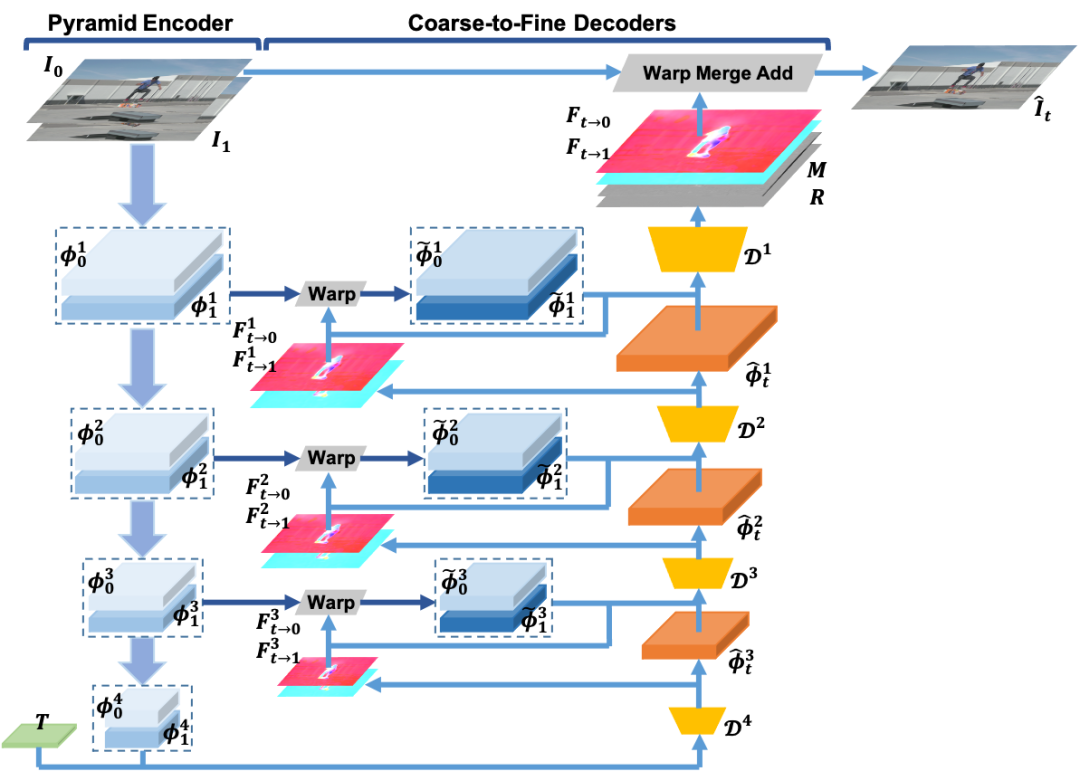
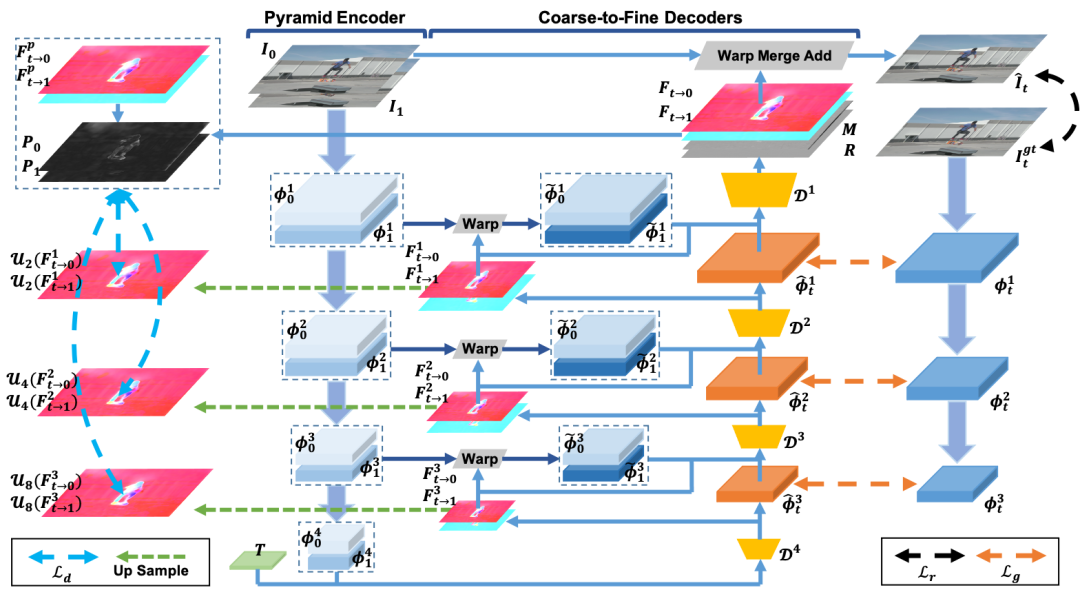
IFRNet网络结构
所提出的IFRNet首先使用encoder网络对两个输入帧分别提取金字塔特征,之后通过coarse-to-fine的多个decoder网络,联合refine双向中间光流和一个具有较强表示能力的中间帧特征,直到达到原始输入分辨率。更准确的中间光流可以backward warp出与目标帧更好对齐的中间帧特征,从而促进中间帧特征重建;另一方面,更好的中间帧特征能够提供更好的锚点(anchor)信息,从而促进中间光流估计。因此,这两者可以相互促进提升。
- 损失函数
1) 图像重建损失:此损失函数为插帧任务的基本损失函数,目的为了使生成的图像符合目标中间帧
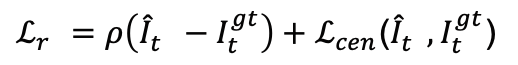
2) 面向任务的光流蒸馏损失:此损失函数通过调整每个像素位置的鲁棒性值来提供更好的面向插帧任务的中间光流监督信息。给定一个现成光流网络的预测结果作为代理标签,我们可以通过公式
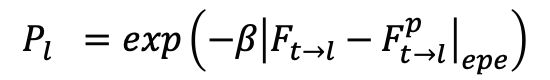
计算出鲁棒性掩码P,并通过该鲁棒性掩码在空间上自适应地调整多尺度光流蒸馏损失函数的鲁棒性形式,以获取面向插帧任务的中间光流监督信息。不同的鲁棒性蒸馏损失函数可参见下图
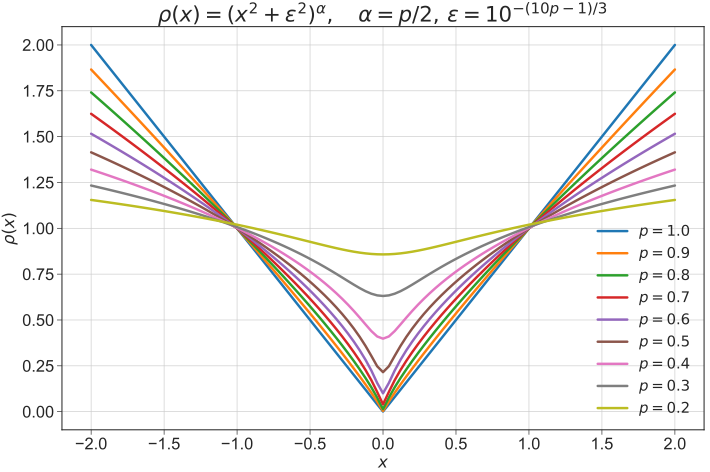
面向任务的光流蒸馏损失可表示为
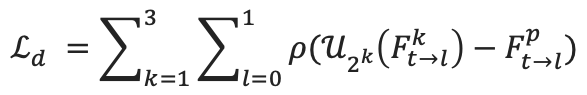
3) 特征空间几何一致性损失:此损失函数用来保持重建的中间帧特征与Ground Truth中间帧特征具有一致的场景几何布局,从而促进最终目标帧合成质量
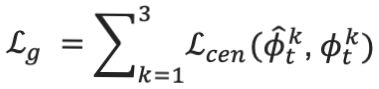
总之,IFRNet整体网络架构与优化损失函数如下图所示
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢