
多模态视频字幕系统利用视频帧和语音来生成视频的自然语言描述(字幕)。这样的系统是朝着构建多模态对话系统的长期目标前进的一步,后者可以轻松地与用户交流,同时通过多模态输入流感知环境。
与关键挑战在于处理和理解多模态输入视频的视频理解任务不同,多模态视频字幕的任务包括生成实用化字幕的额外挑战。这项任务被采用最广泛的方法是使用手动注释数据联合训练编码器 - 解码器网络。
然而,由于缺乏大规模的人工标注数据,为视频注释可用字幕的任务是非常耗费人力的,在许多情况下不切实际。VideoBERT 和 CoMVT 等先前的研究通过利用自动语音识别(ASR)对未标记视频的模型进行预训练。然而,此类模型通常无法生成自然语言句子,因为它们缺少解码器,因此只有视频编码器被转移到下游任务。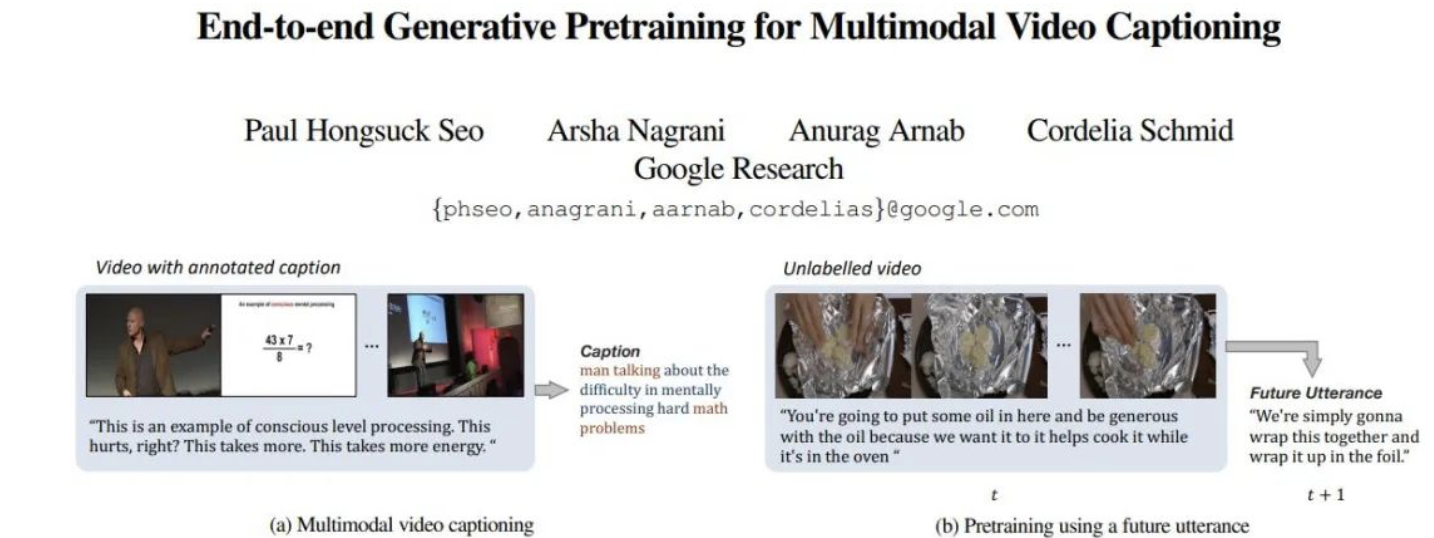
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢